Transformers is a family of Deep Learning models, generally used for NLP, that share a similar architecture, similar features such as attention and similar learning methods (such as semi supervised learning).
After being trained using semi supervised learning, the transformers can be fine tuned on specific tasks using transfer learning and labelised data.
A transformer is composed of an encoder and/or a decoder:
For example for a translation task, during training, the decoder uses as input the sentence in the translated language (with mask in order to not see the word it needs to predict) coupled with the encode information from the encoder. It uses all of that to predict the next word. In inference it has not access to the true label of the precedent translated words and then is uses its own predicted words as an approximation.
Encoder models only uses the encoder part of a Transformer. At each stage, the attention layers can access all the words in the initial sentence. These models are often characterized as having “bi-directional” attention, and are often called auto-encoding models.
The pretraining of these models usually revolves around somehow corrupting a given sentence (for instance, by masking random words in it) and tasking the model with finding or reconstructing the initial sentence.
These models are best suited for tasks requiring an understanding of the full sentence, such as sentence classification, named entity recognition (and more generally word classification), and extractive question answering.
Example of models: BERT, ALBERT, ROBERTa, DistilBERT, ELECTRA …
Decoder models use only the decoder of a Transformer model. At each stage, for a given word the attention layers can only access the words positioned before it in the sentence. These models are often called auto-regressive models.
The pretraining of decoder models usually revolves around predicting the next word in the sentence.
These models are best suited for tasks involving text generation.
Example of models: GPT, GPT-2, CTRL, Transformer XL, …
Encoder-decoder models (also called sequence-to-sequence models) use both parts of the Transformer architecture. At each stage, the attention layers of the encoder can access all the words in the initial sentence, whereas the attention layers of the decoder can only access the words positioned before a given word in the input.
The pretraining of these models can be done using the objectives of encoder or decoder models. However more complex task are used such as predicting masked words in a sentence.
Sequence-to-sequence models are best suited for tasks revolving around generating new sentences depending on a given input, such as summarization, translation, or generative question answering.
Example of models: BART, mBART, Marian, T5, …
Here is the architecture of the original paper introducing transformers:
The left part is the encoder and the right part is the decoder.
Different important parts of a transformers appears:
The grey blocks are repeated \(N\) times, the output of one block being the input of the next block.
Let’s detail the different parts of a transformer (see this page for the presentation of the concept of attention).
The Transformer uses basic feed forward layers (ie fully connected layers) after self-attention:
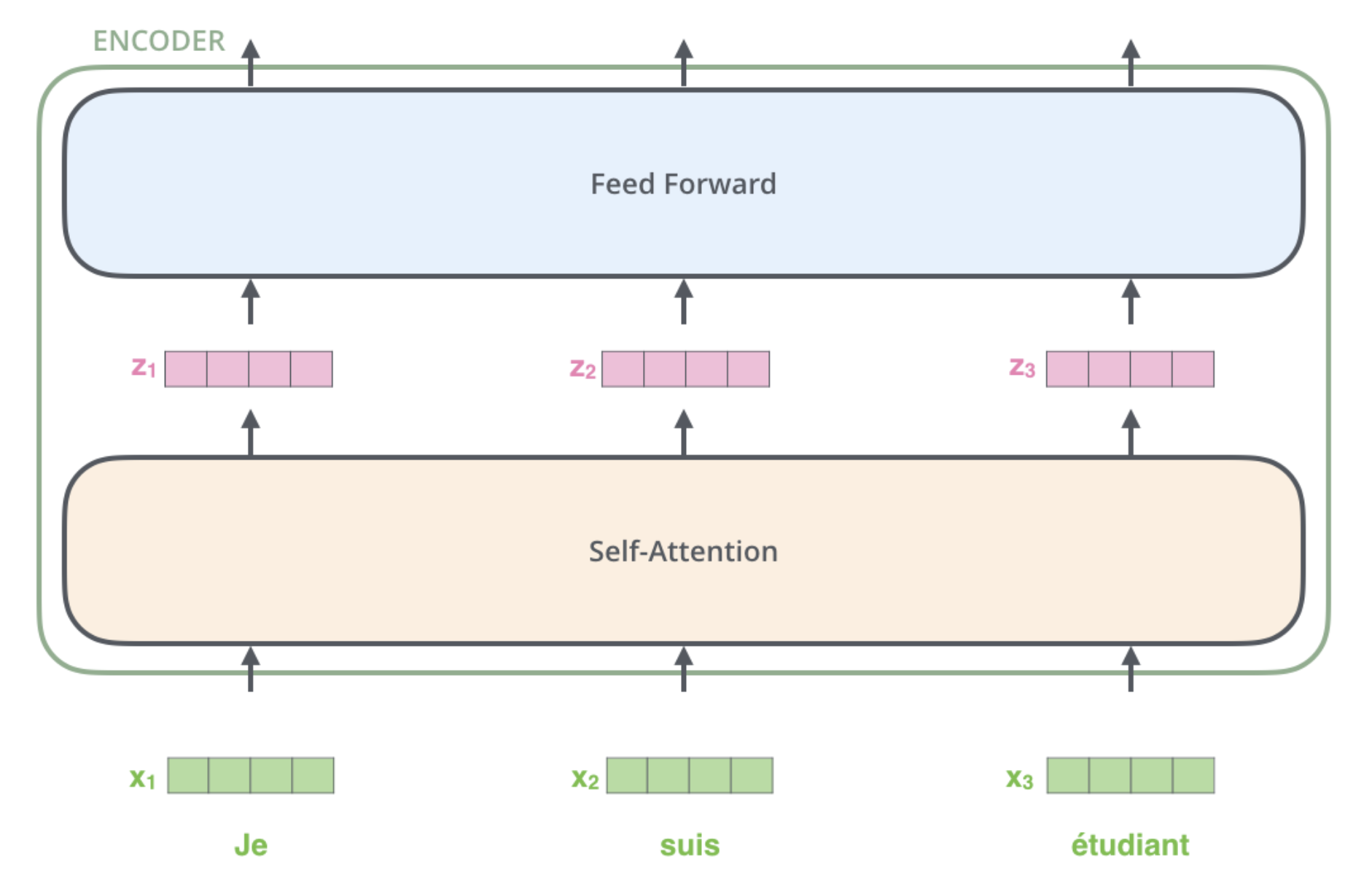
The output of a feed forward layer is used as input for the next block:
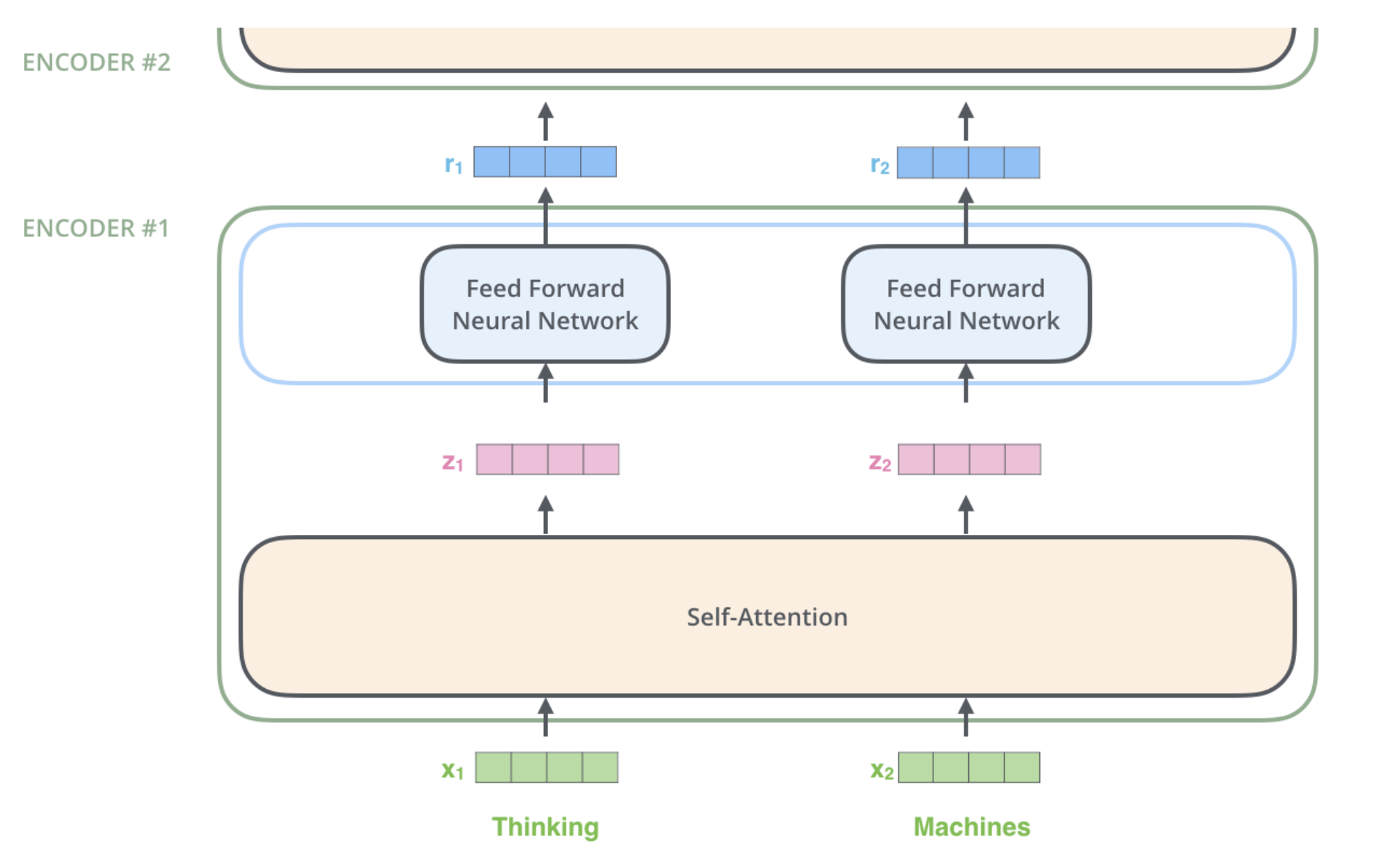
Transformer uses residual blocks to allow better gradient flow (the dot lines):
Last layer of a transformer is a linear block followed by a softmax function (ie a multi-class logistic regression). In next word prediction, it outputs a probability for each word of the vocabulary:
The loss for encoder is cross-entropy Cross-Entropy.
See: