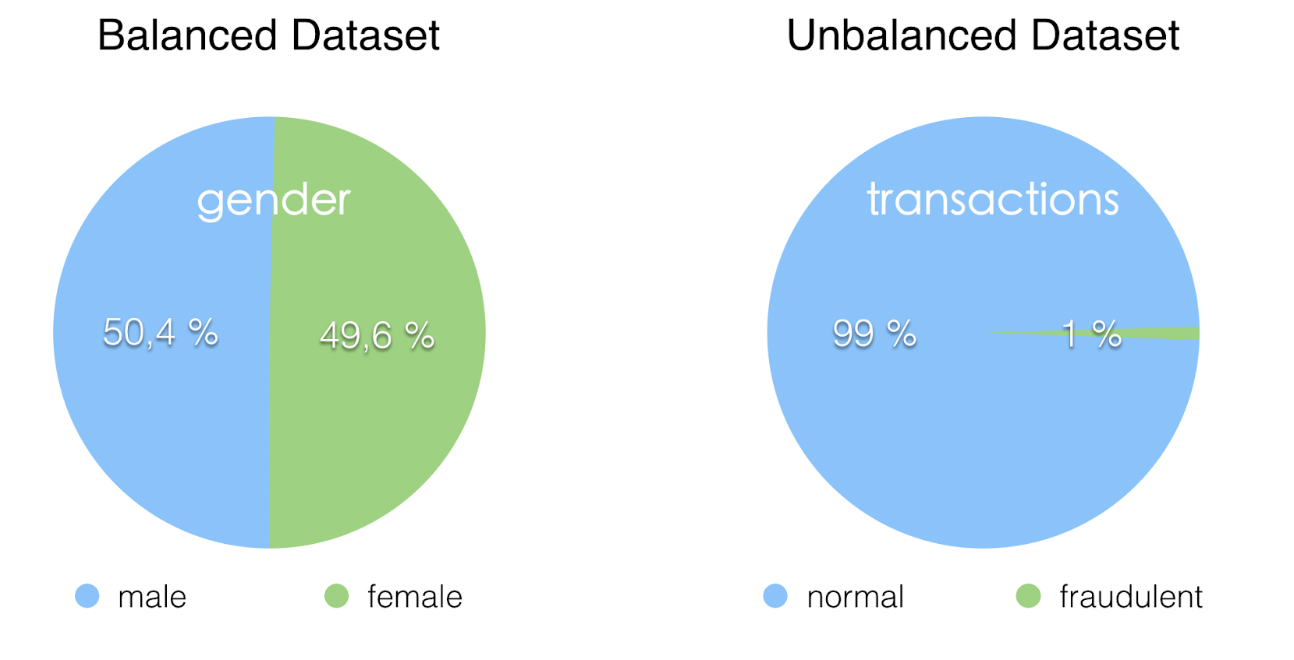
Unbalanced data is common problem in classification problem in which the proportions of data from each class are very unbalanced. One of the class (majority class) is over represented and/or one the class (minority class) is under represented.
In can occurs in binary classification or multiclass classification.
Unbalanced data are vert common in the real world application of classification.
On typical example is fraud detection:
A widely adopted technique for dealing with highly unbalanced datasets is called resampling. It consists of removing samples from the majority class (under-sampling) and / or adding more examples from the minority class (over-sampling).
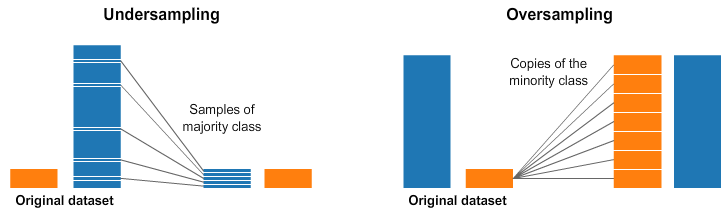
Despite the advantage of balancing classes, these techniques also have their weaknesses (there is no free lunch). The simplest implementation of over-sampling is to duplicate random records from the minority class, which can cause overfitting. In under-sampling, the simplest technique involves removing random records from the majority class, which can cause loss of information.

Tomek links are pairs of very close instances, but of opposite classes. Removing the instances of the majority class of each pair increases the space between the two classes, facilitating the classification process.
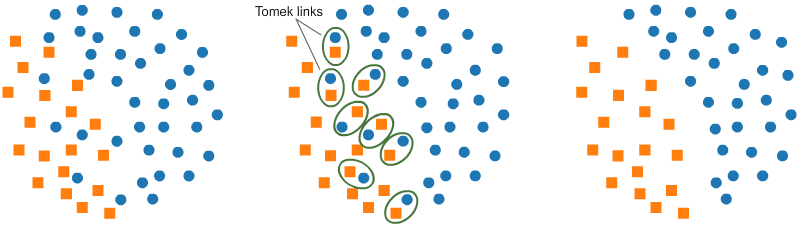
See:
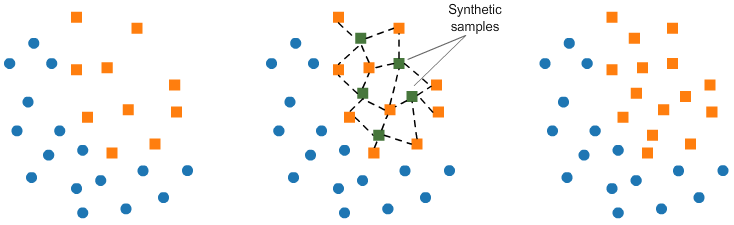
SMOTE (Synthetic Minority Oversampling TEchnique) consists of synthesizing elements for the minority class, based on those that already exist. It works randomly picking a point from the minority class and computing the \(k\)-nearest neighbours for this point. For each chosen point, \(N\) synthetic points are added between the chosen point and its neighbours. Each synthetic point is added randomly on the line between the chosen point and one of its neighbours.
General view:
Visualisation of the creation of 1 synthetic point:
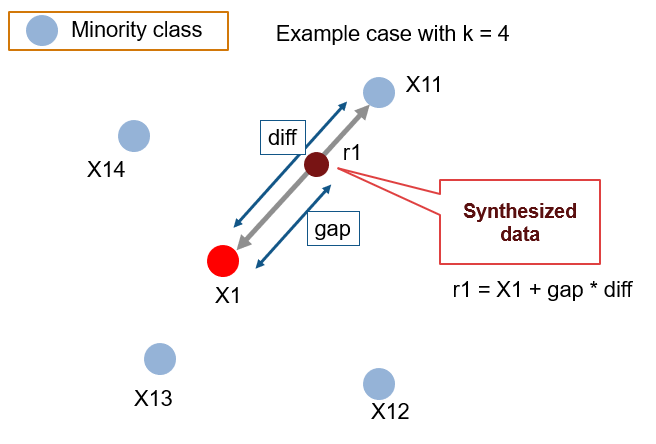
\(gap\) is a random value between \(0\) and \(1\).
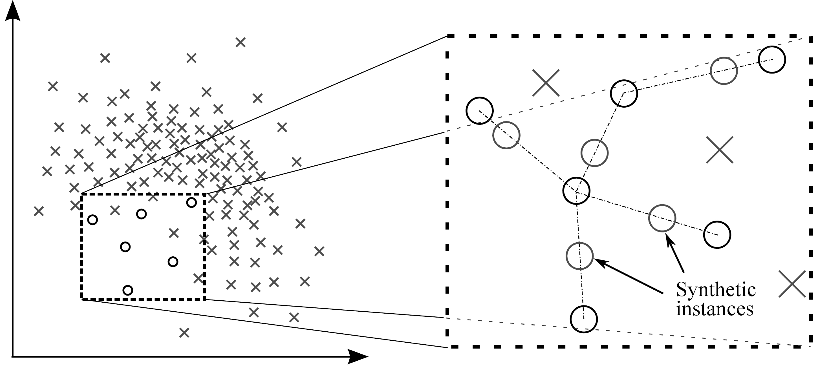
Another view that combines global and specific view:

See:
The idea of algorithm level methods is that training samples we care about should contribute more to the loss.
Back in 2001, based on the insight that misclassification of different classes incur different cost, Elkan proposed cost-sensitive learning where the individual loss function is modified to take into account this varying cost.

Class-balance loss gives more weight to rare classes.

Focal loss gives more weights to difficult sample. See Focal loss in the machine learning losses page.
See: