In classification, the output of a model represent the probability of different outcomes. Generally it is the probability for the input to belong to a given class.
Depending on the number of possible classes we use a sigmoid or a softmax function in order to insure that our outputs sum to 1.
The sigmoid and softmax functions are not so similar but it can be shown that sigmoid is just a special case of softmax.
Softmax insures that the outputs of a multi class model sum to 1.
Imagine a problem with 3 possible classes. Our model will give a score to each of the class. In the end what we want to know is ‘what is the class of this input?’ (is it a cat, a dog or a rabbit, …).
The softmax function will take \(K\) scores as input and normalize them to make them sum to 1:
Where:
Sigmoid insures that the outputs of a binary class model sum to 1. When dealing with binary class problems with two class 0 and 1, we just look at the probability for an input of being of class 1. The probability of being of class 0 is juste the complement.
\[\sigma(z) = \frac{1}{1+e^{-z}} = \frac{e^{z}}{e^{z}+1}\]Where:
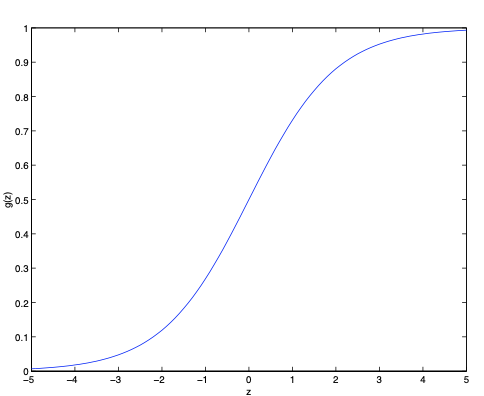
Here is a plot showing \(\sigma(z)\):
The derivative of \(\sigma(z)\) is:
\[\begin{eqnarray} \frac{d\sigma(z)}{dz} &&= \frac{d}{dz}\frac{1}{1+e^{-z}} \\ &&= \left(-\frac{1}{\left(1+e^{-z}\right)^2}\right)\left(-e^{-z}\right) \\ &&= \left(\frac{1}{\left(1+e^{-z}\right)^2}\right)\left(e^{-z}\right) \\ &&= \frac{1}{1+e^{-z}}\frac{1}{1+e^{-z}}\left(1+e^{-z}-1\right) \\ &&= \frac{1}{1+e^{-z}}\left(\frac{1+e^{-z}}{1+e^{-z}}-\frac{1}{1+e^{-z}}\right) \\ &&= \frac{1}{1+e^{-z}}\left(1-\frac{1}{1+e^{-z}}\right) \\ &&= \sigma(z)\left(1-\sigma(z)\right) \end{eqnarray}\]The format of the derivative is useful in some computations (for Logistic regression for example).
In binary classification we compare the probability of being of one class vs the other.
It is equivalent of comparing the input (the score) of class 1 vs the score of class 0. In binary classification the score of class 0 is just set to 0. Then the comparison is juste to compare the score of class 1 vs 0. If the score of class 1 is greater than 0 then its probability is greater than 0.5 and it is lower than 0.5 otherwize.
Using this fact, the link with softmax is obvious:
\[\begin{eqnarray} \sigma(z)_1 &&= \frac{e^{z_1}}{e^{z_0} + e^{z_1}} \\ &&= \frac{e^{z_1}}{e^0 + e^{z_1}}\\ &&= \frac{e^{z}}{1 + e^z} = \frac{1}{1+e^{-z}} = \sigma(z) \end{eqnarray}\]And for class 0:
\[\begin{eqnarray} \sigma(z)_0 &&= \frac{e^{z_0}}{e^{z_0} + e^{z_1}}\\ &&= \frac{e^0}{e^0 + e^{z_1}}\\ &&= \frac{1}{1 + e^z}\\ &&= \frac{e^{-z}}{1+e^{-z}}\\ &&= \frac{1+e^{-z}-1}{1+e^{-z}}\\ &&= \frac{1+e^{-z}}{1+e^{-z}} - \frac{1}{1+e^{-z}} \\ &&= 1 - \frac{1}{1+e^{-z}} = 1 - \sigma(z) \end{eqnarray}\]Starting from the Softmax formulation we finally obtain the sigmoid formulation.
The Logit function is the inverse of the sigmoid function.
It is the function \(logit\) such that \(logit(g(z))=z\) (for \(g\) the sigmoid function).
\[logit(p) = \log\left(\frac{p}{1-p}\right) \forall p \in ]0, 1[\]Here is a plot showing \(logit(p)\) (called \(f(x)\) in the plot):

Logistic regression is called a regression as their exit a linear relation between the input data \(X\) and the logit of the prediction made by the model.
See: