
Data Augmentation are methods to synthetically augment the quantity of data.
Label-preserving transformations modify a bit a date without changing its label. It is widely used in computer vision and NLP.

Small perturbations can be added to data in order to make the classification difficult.

From DeepFool: a simple and accurate method to fool deep neural networks by SM Moosavi-Dezfooli et al..
BERT has been trained on data with pertubations and has been trained on finding the right word in place of the pertubation:

Since collecting data is expensive and slow with many potential privacy concerns, it’d be a dream if we could sidestep it altogether and train our models with synthesized data. Even though we’re still far from being able to synthesize all training data, it’s possible to synthesize some training data to boost a model’s performance.
In computer vision, a straightforward way to synthesize new data is to combine existing examples with discrete labels to generate continuous labels. Consider a task of classifying images with two possible labels: DOG (encoded as 0) and CAT (encoded as 1). From example \(x_1\) of label DOG and example \(x_2\) of label CAT, you can generate \(x'\) such as:
\[x' = \gamma x_1 + (1 - \gamma) x_2\]The label of \(x'\) is a combination of the labels of \(x_1\) and \(x_2\) : \(\gamma \times 0 + (1 - \gamma) \times 1\). This method is called mixup. The authors showed that mixup improves models’ generalization, reduces their memorization of corrupt labels, increases their robustness to adversarial examples, and stabilizes the training of generative adversarial networks.

Mixup us useful for:
In NLP, templates can be a cheap way to bootstrap your model. It is possible to bootstrap training data for a conversational AI (chatbot). A template might look like: “Find me a [CUISINE] restaurant within [NUMBER] miles of [LOCATION].” With lists of all possible cuisines, reasonable numbers (you would probably never want to search for restaurants beyond 1000 miles), and locations (home, office, landmarks, exact addresses) for each city, you can generate thousands of training queries from a template.

GAN are neural networks that are trained to fool a classification network not to recognize if the data is a real data or has been generated by the GAN network.
Both network (discrimant and GAN) are trained in the same time and if the discrimant is better and better at recognizing real data compare to generated data, then the GAN will improve, and then the discriminator will improve again, etc.
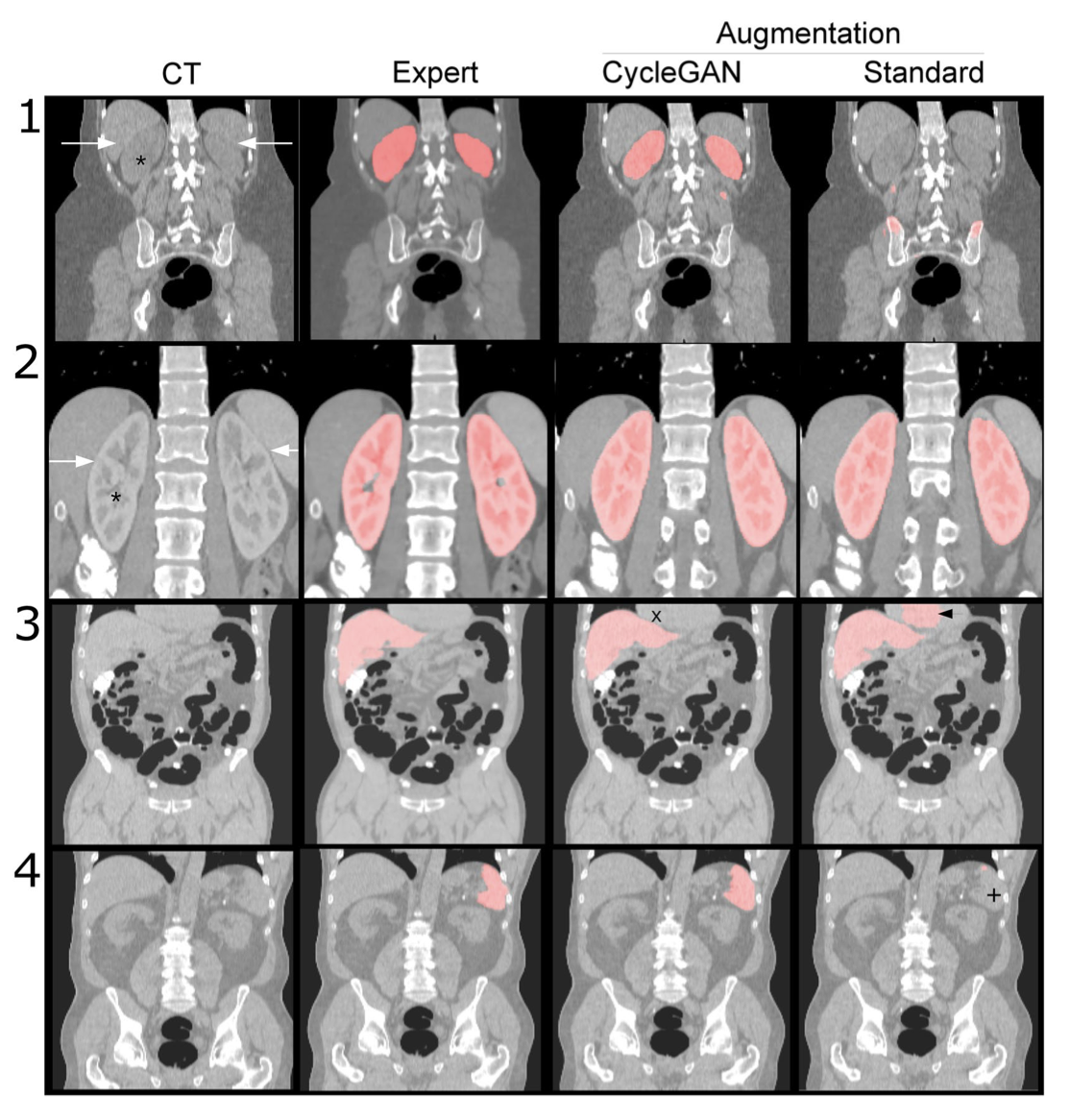
Data augmentation using GAN. Results from model trained on augmented data using GAN vs expert and standard training. From Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks by V Sandfort et al..
See: