BERT is a Transformer model using the Encoder part.
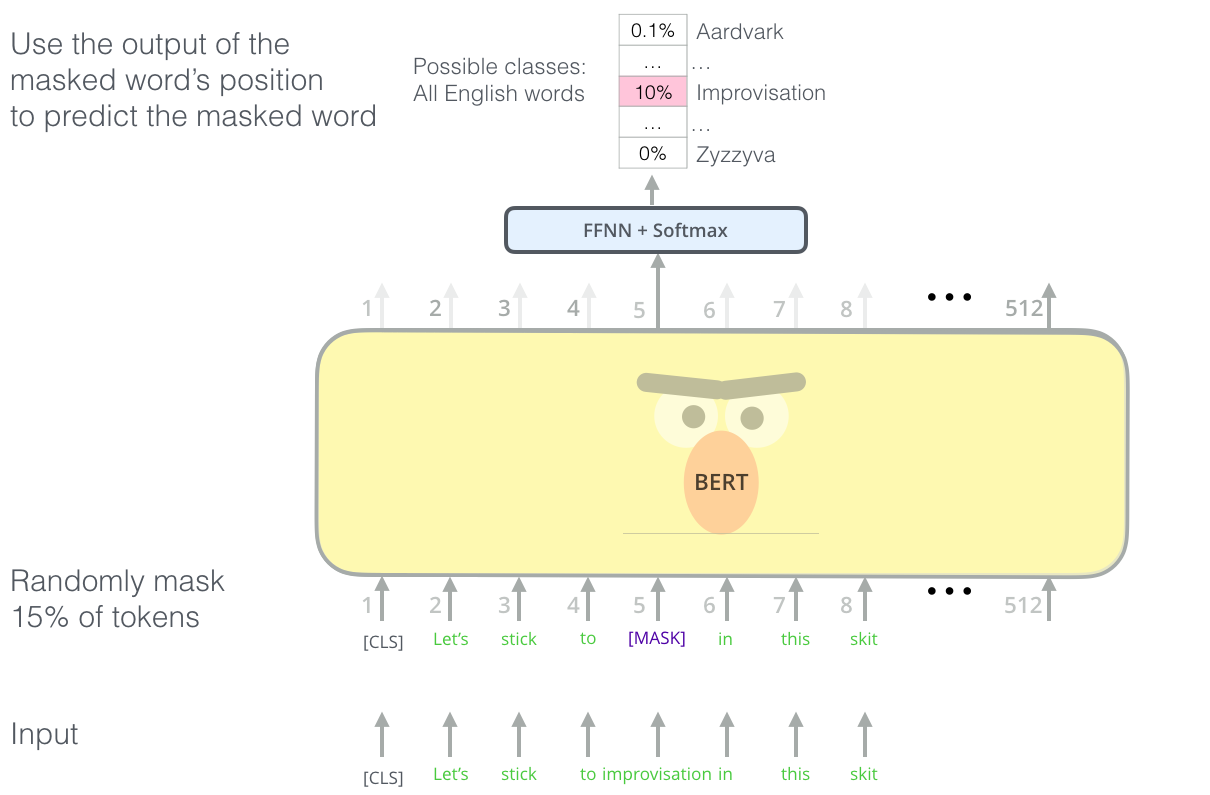
Major innovation in BERT comes from the way it has been trained in a semi-supervised fashion. Indeed, using the encoder part, the model has access to every words of a text ant this a problem to perform semi-supervised training (ie without external data or labels) like predict a specific word in the text (as an encoder has access to all of the input ie to this word).
The idea of BERT is to use a mask block to mask a word it will later predict. It can also replace a word in a text by any word of the vocabulary and be asked to predict the true word that should be at this position:
Another task used to train BERT is to predict if a given sentence is the following sentence of another sentence:

The label can be automatically extract and training data automatically generated (hence it is semi-supervised learning).
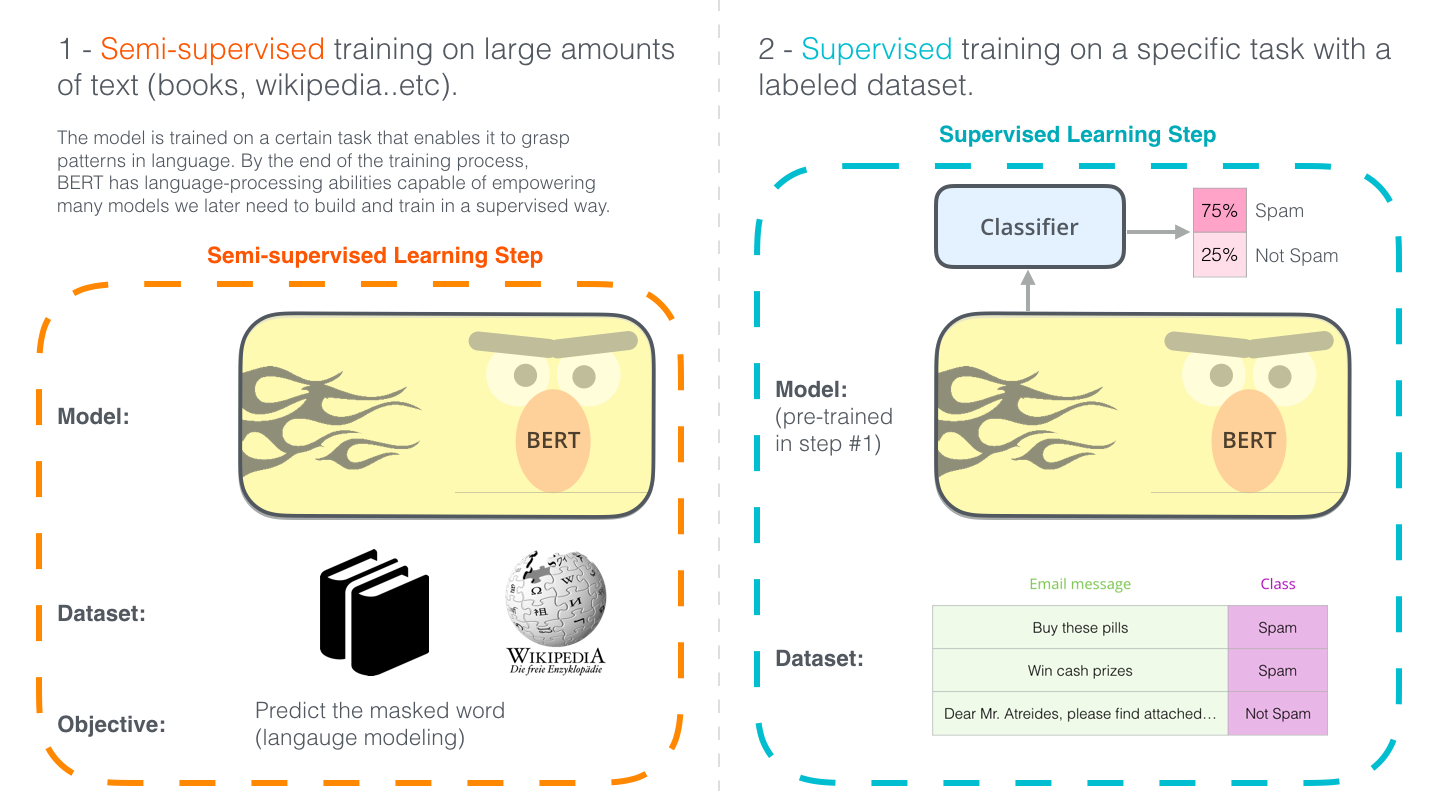
Using these methods BERT can be trained in a semi-supervised fashion.
Once BERT has been trained using semi-supervised training on large amount of data it can be fine-tuned to perform any supervised nlp task:
See: