Policy based methods get rid of the estimation of the action value function to estimate the optimal policy and just directly estimate the optimal policy.
Here is a comparison of value based methods and policy based methods.
Value based methods estimate:
And then they compute the policy using \(\varepsilon\)-greedy method for stochastic policies (or greedy method for deterministic policies).
Policy based methods estimate directly the policy:
As policy based methods does not compute estimated return for each action it can generalize to action with continuous space.
Action based method relied on discretisation of the action space to deal with continuous action space and it is very inefficient (specifically to choose the best action over a large number of possible actions).
It is more natural to directly estimate the best policies instead of deriving it from an estimated action value function.
Policy based methods can generate true stochastic policy instead of adding randomness using the \(\varepsilon\)-greedy method.
Compare to the DQ network which outputs a estimated returns for each action, a policy based method will directly output a probability for each action.
REINFORCE (Monte-Carlo policy gradient) is a policy gradient method.
Policy gradient method are a sub class of policy based methods that researche the best policy using the stochastic gradient ascent method (similar to stochastic gradient descent but to find maximum values).
Gradient ascent update rule is:
\[\theta = \theta + \alpha \nabla_\theta U(\theta)\]Where:
Policy gradient methods introduce:
Let’s also introduce:
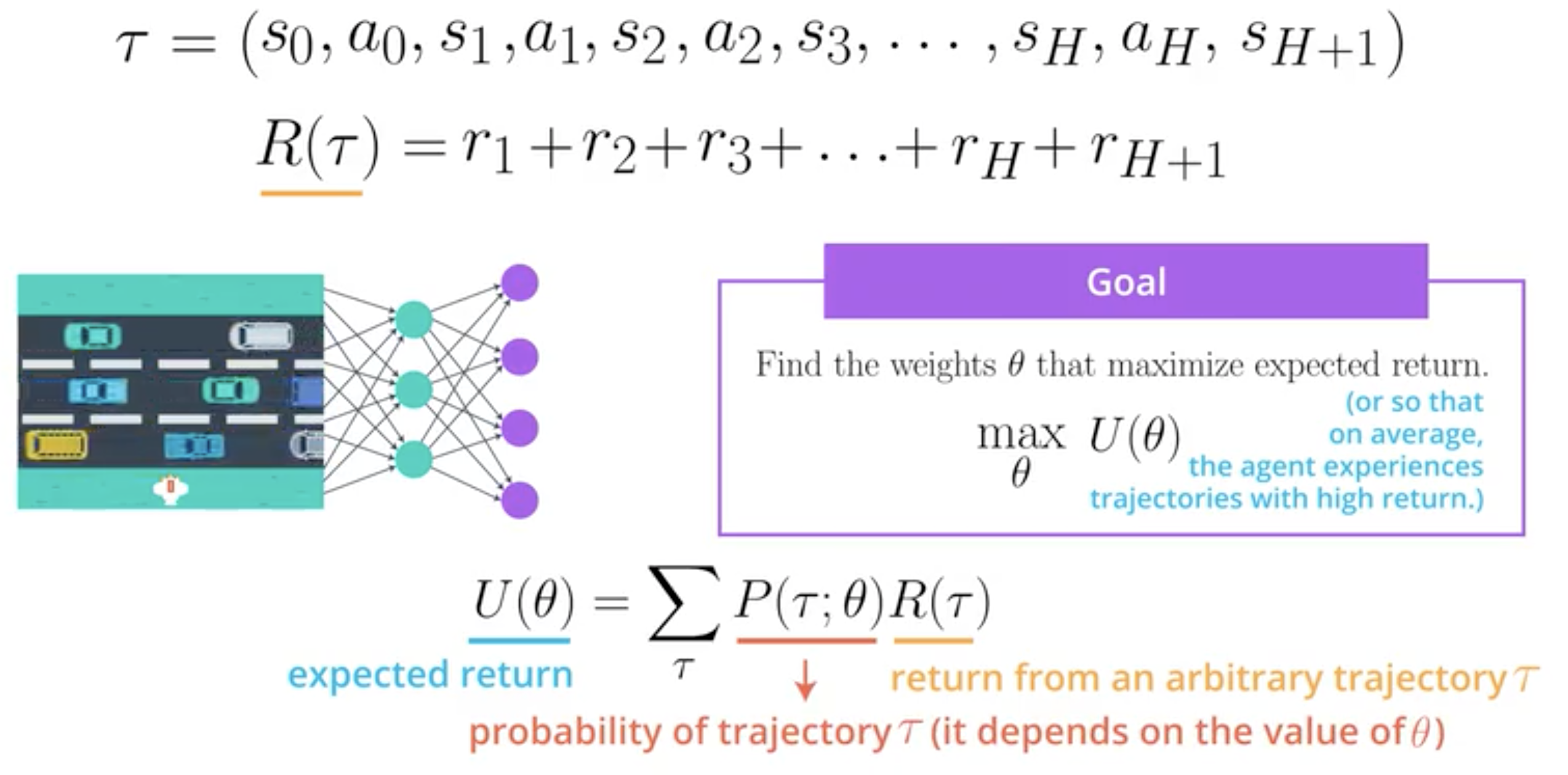
The problem is hence to find the set of parameters \(\theta\) that maximises the expected return \(U(\theta)\):
Here is a vulgarisation of the algorithm of the policy gradient method:
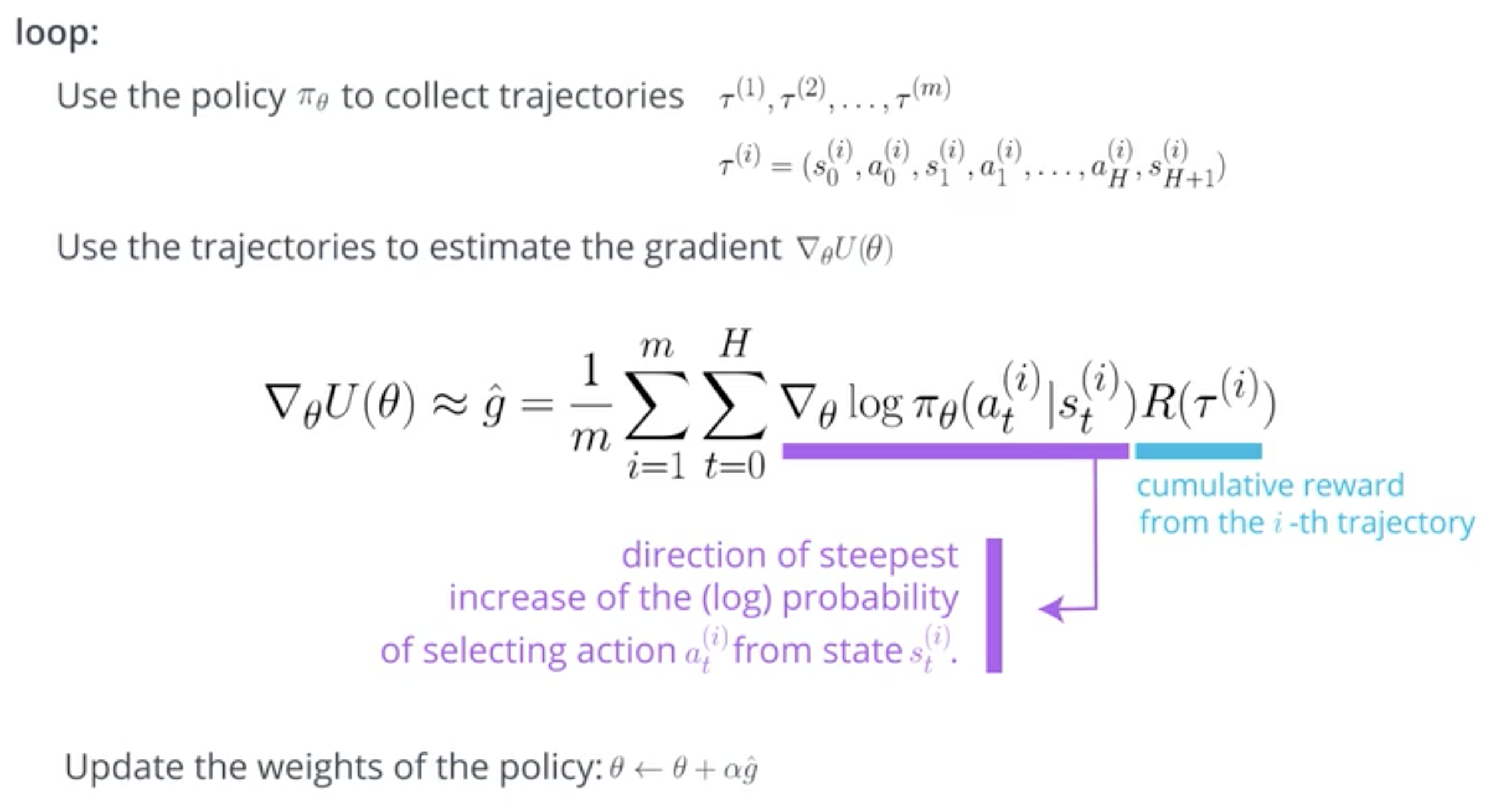
The proof is in the appendice: proof of REINFORCE gradient. It comes from this Medium blog post by Chris Yoon.
Alternative proofs can be found on this blog post by Lilian Weng or Reinforcement Learning: An Introduction by Sutton and Barto.
Apart from the derivative that is not obvious to obtain, this is a classic application of gradient ascent.
See: