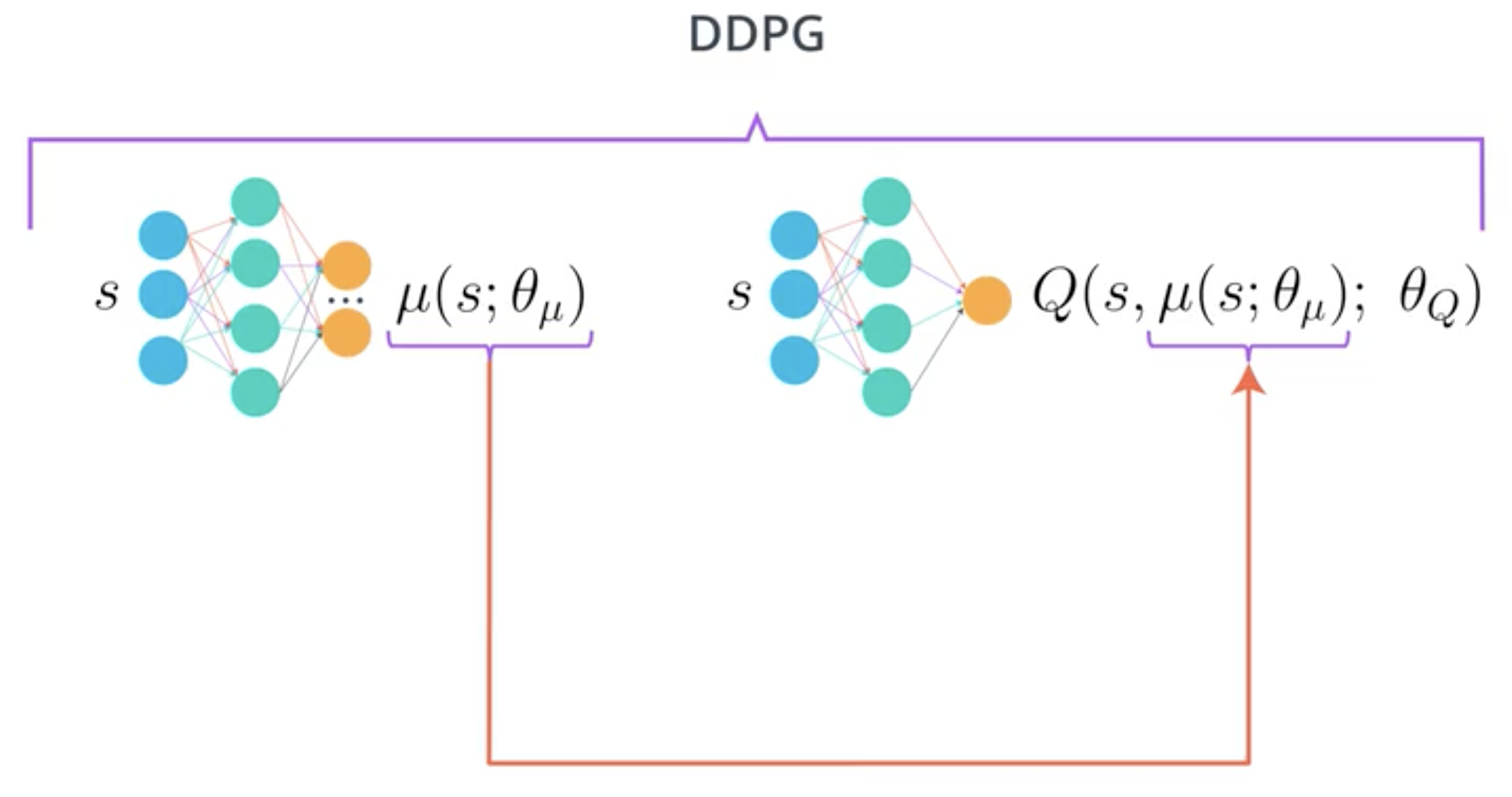
Deep Deterministic Policy Gradient method (DDPG) is an actor critic model used to deal with continuous action space.
Unlike the other actor critic methods using a DQN like model to estimate a distribution probability over the possible action, DDPG directly estimates the best possible action in a deterministic way (in practice a noise is added to the selected action - remember that we are now in a continuous space).
The main advantage of outputing the best possible action is that DDPG can easily deal with continous space action function, the other methods generally output a probability for a finite list of actions.
DDPG is an actor critic method:
Here is an image of DDPG:
The function \(\mu(s, \theta_\mu)\) outputs the best possible action given policy \(\pi_\theta\) and state \(s\):
\[\mu(s, \theta_\mu) = arg\max_{a}Q(a,s)\]The critic \(Q\) uses this action, the recevied reward and the next state to update its parameters using TD estimate. It also estimates the action value function and the advantage value function which will then be used to train the actor.
Both actor and critics use a regular and a target network. Unlike in the DQN model, these networks are softly updated (instead of being updated evert \(C\) steps):

DDPG also relies on Batch normalization to normalize the outputs of layers and obtain better gardient smoothing.
See: