A3C for Asynchronous Advantage ActorCritic is an actor critic model with some tricks to improve training of the network.
It uses an actor that maintain the policy and interact with the environment and an critic that computes the advantage function that the actor will use to update its parameters.
n-steps Bootstraping is a generalisation of TD estimate for more than one step.
Vanilla TD estimate for a state \(s\) and an action \(a\) uses the obtained reward \(s\) and the state value function of next state \(s'\) to update the parameters. It computes the advantage function \(A(s,a)\) only using these 2 informations (reward and next state):
\[A_{\theta_V}(s,a) = r + \gamma V_{\theta_V}(s') - V_{\theta_V}(s)\]n-steps Bootstraping uses the same ideas but uses n steps instead of one step:
\[A_{\theta_V}(s,a) = \sum_{i=1}^{n} \gamma^{i-1} r_i + V_{\theta_V}(s^n) - V_{\theta_V}(s)\]It allows to reduce biais of TD estimate and keeping low variance in the same time.
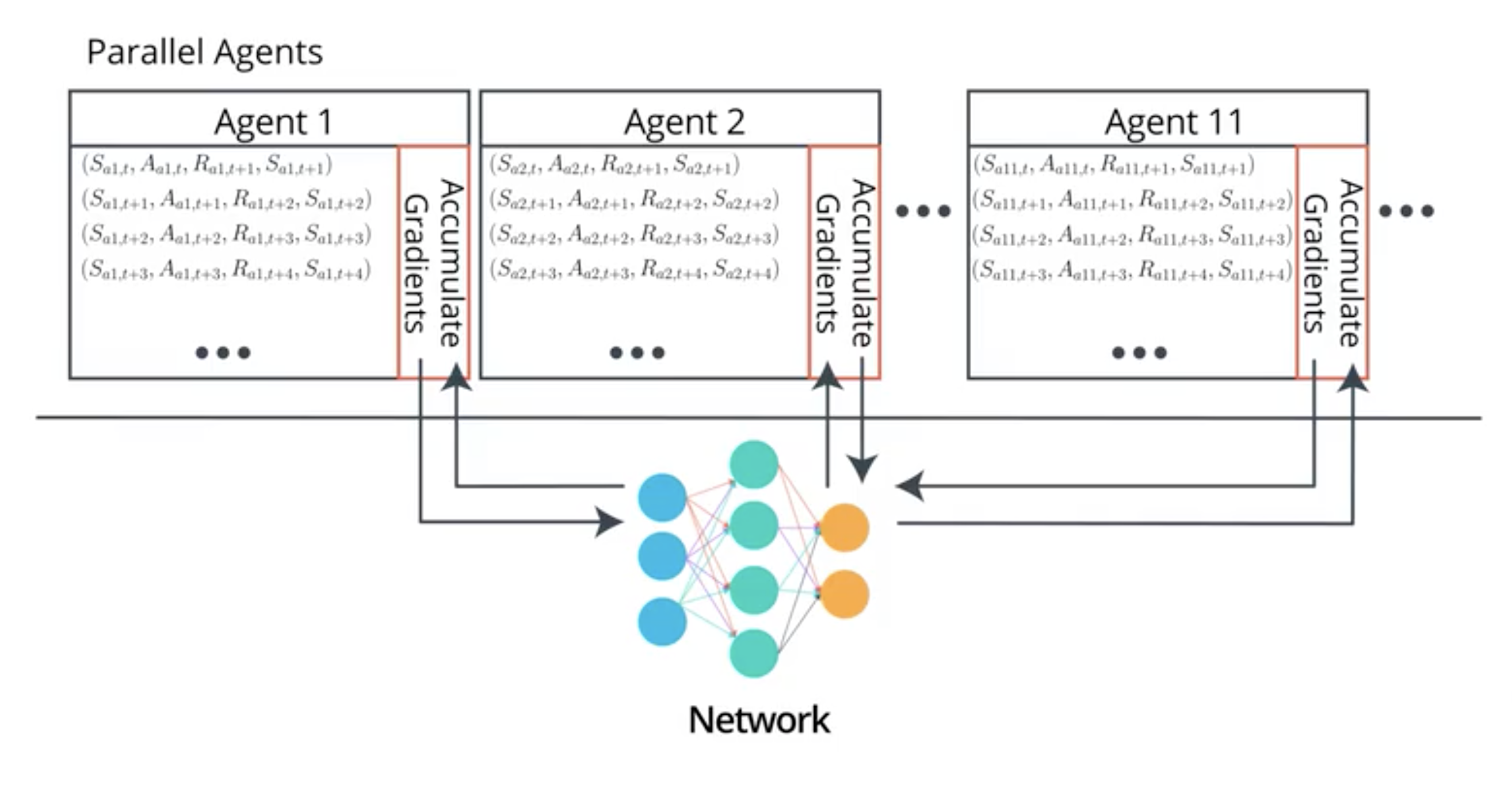
A3C replaces experience replay by parallel training:
The model uses different agent to train its weights. Each agent uses sequence of state and actions that are correlated but the decorrelation comes from the use of different agents.
The updates of the parameters of the model are done asynchronously that means that each agent sends its gradients at different time and the model makes updates every time its receives a gradient. Their is no synchonisation among the agents.
Parallel training is a on-policy learning algorithm as the training replicates exactly the interaction with the environment.
On the other hand, experience replay, buy cutting the sequence in small pieces, does not replicate the interaction with the environment in its training process hence it is a off-policy learning.
On-policy learning is more stable and have more consitent convergeance particularly with deep neural networks.
See: Sarsa and Sarsamax as on and off policy methods.
The actor and the critic can share the same first layers of the network. It is especially useful for Convolutional Neural Network where both actor and critic need to understand the visible environment.
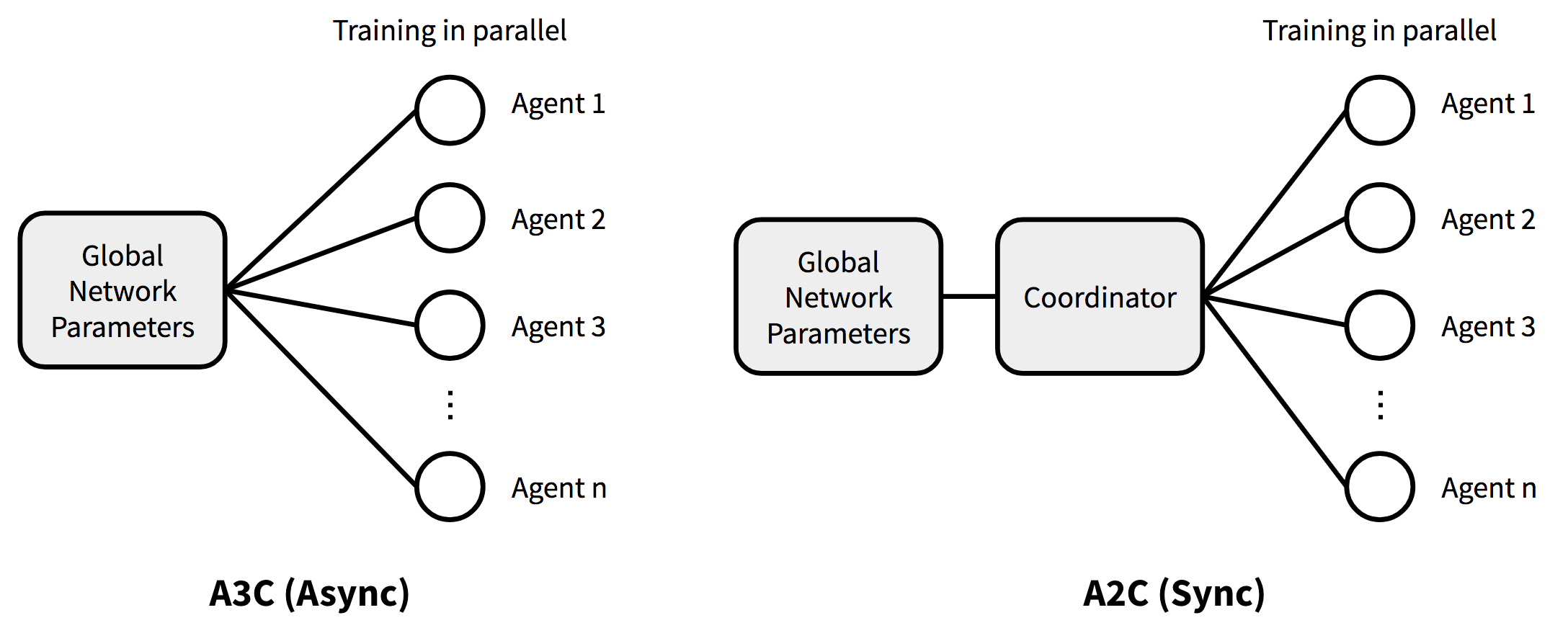
The only difference between A2C and A3C is that the parallel computing is done synchonously among agents in A2C and asynchronously among agents for A3C.
A3C is easier to train on CPU and A2C on GPU. A2C works better with large bactch sizes.
Here is an illustration of the difference:
See: