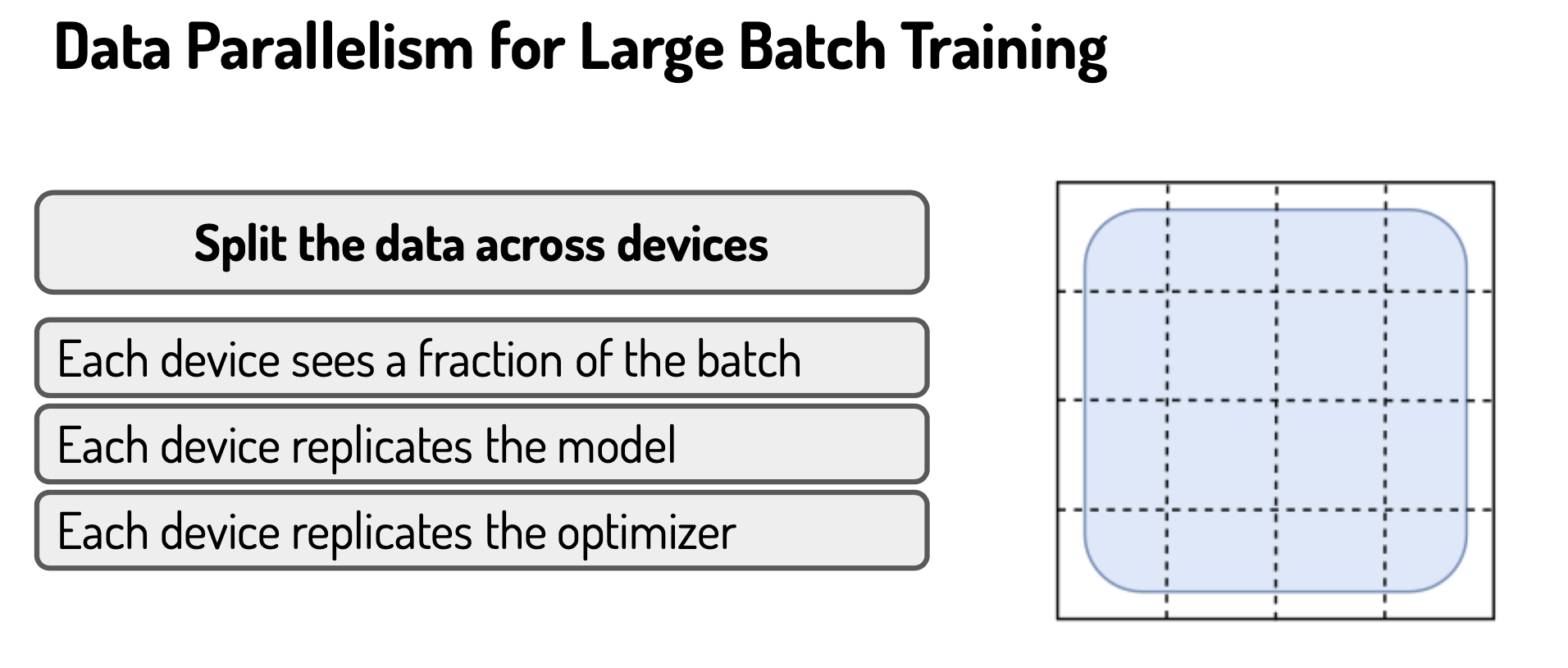
How to split data across different devices durint training?
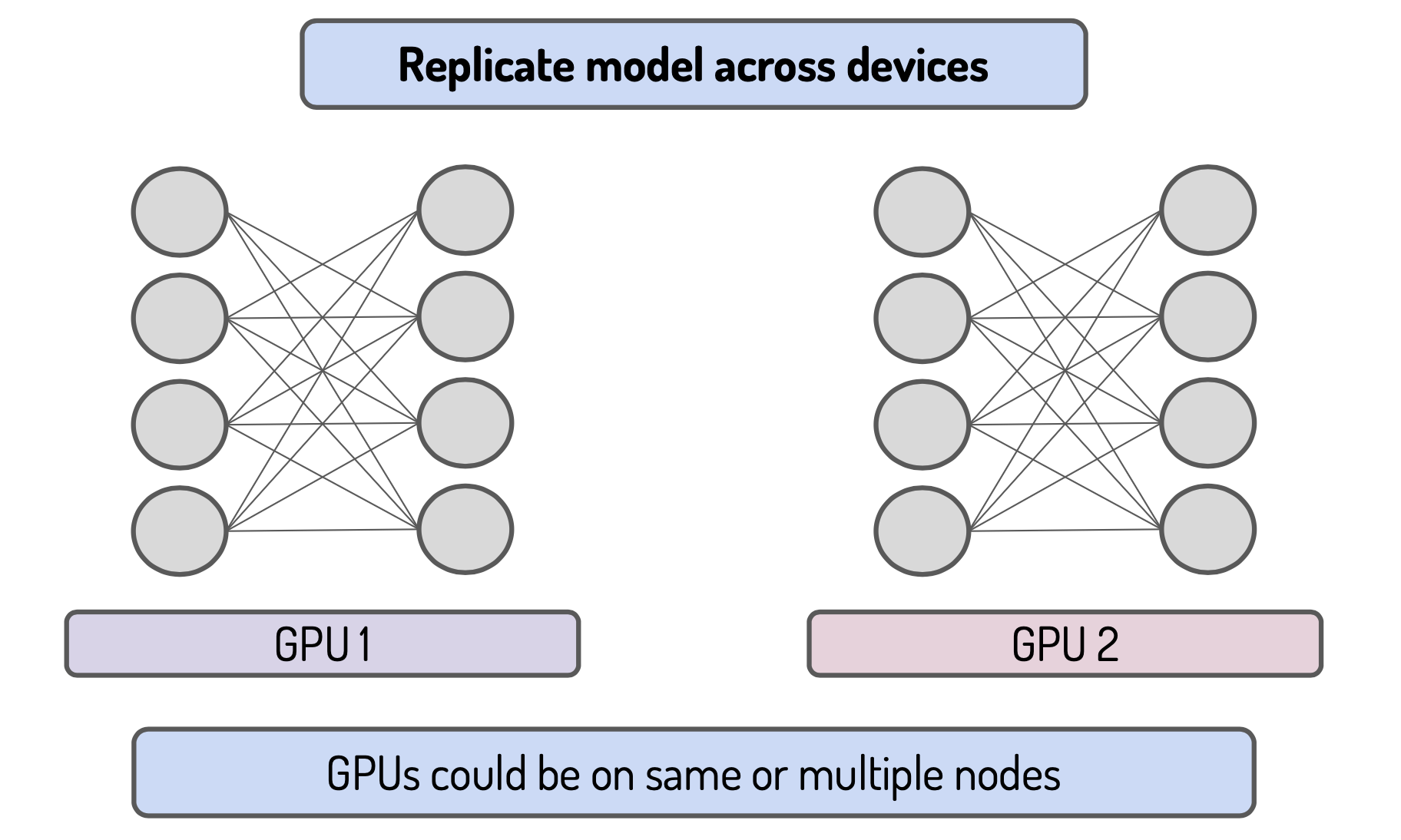
First is to replicate the model on the different devices:
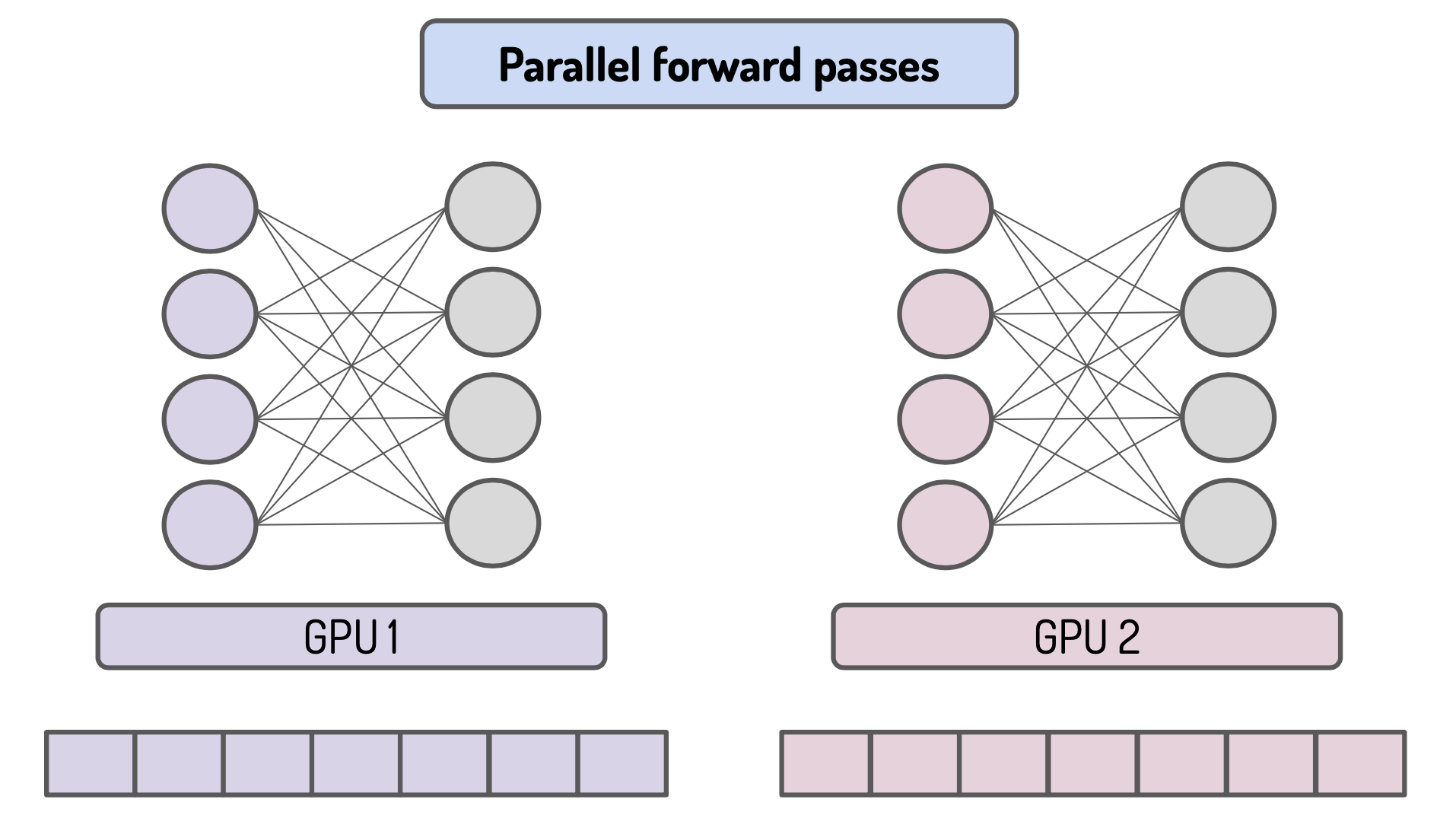
Second the forward pass is done in parallel on the different devices with different batch of data:
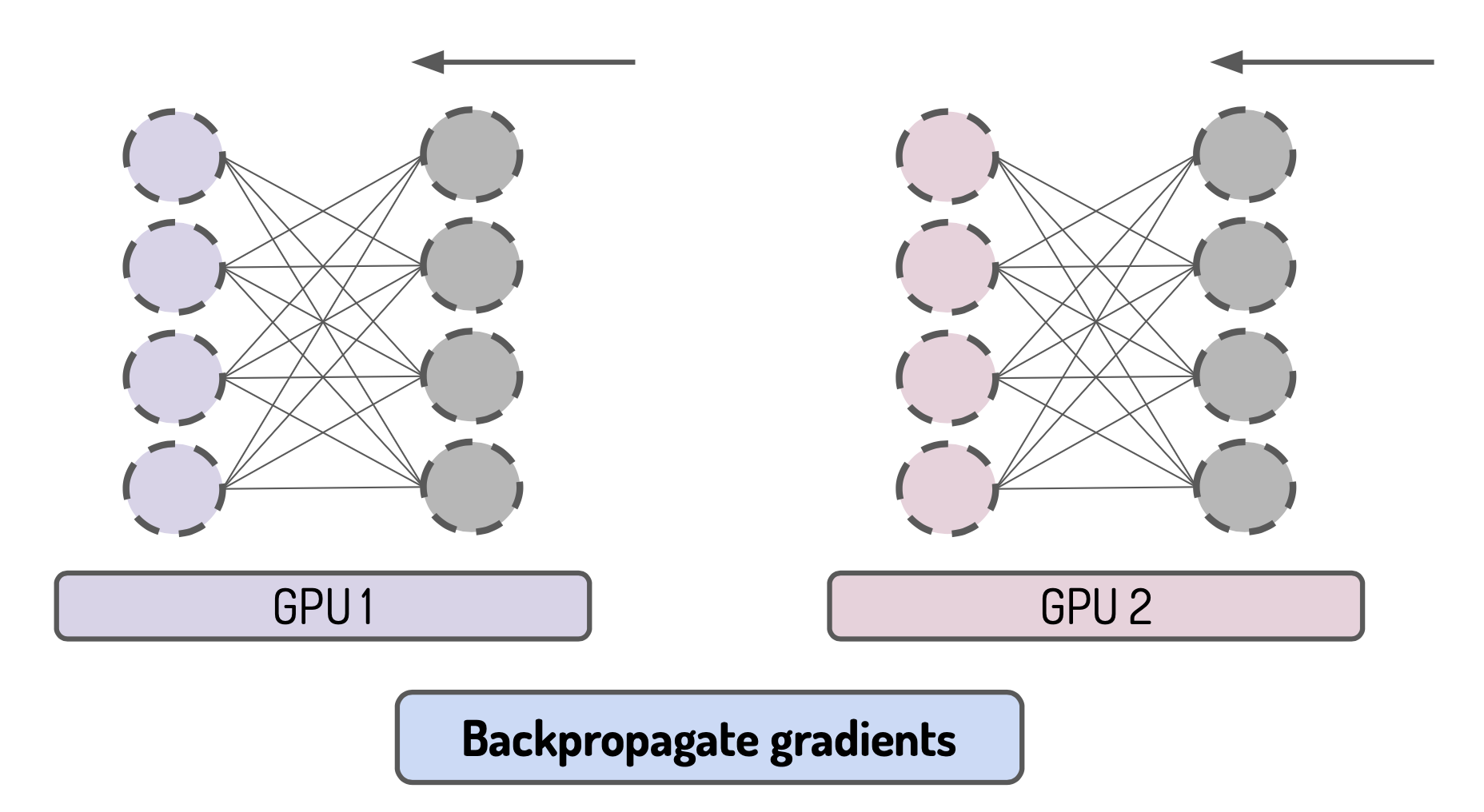
Third the gradient are backpropagated on each device (but the parameters are not updated):
Fourth the gradient are averaged across every devices:
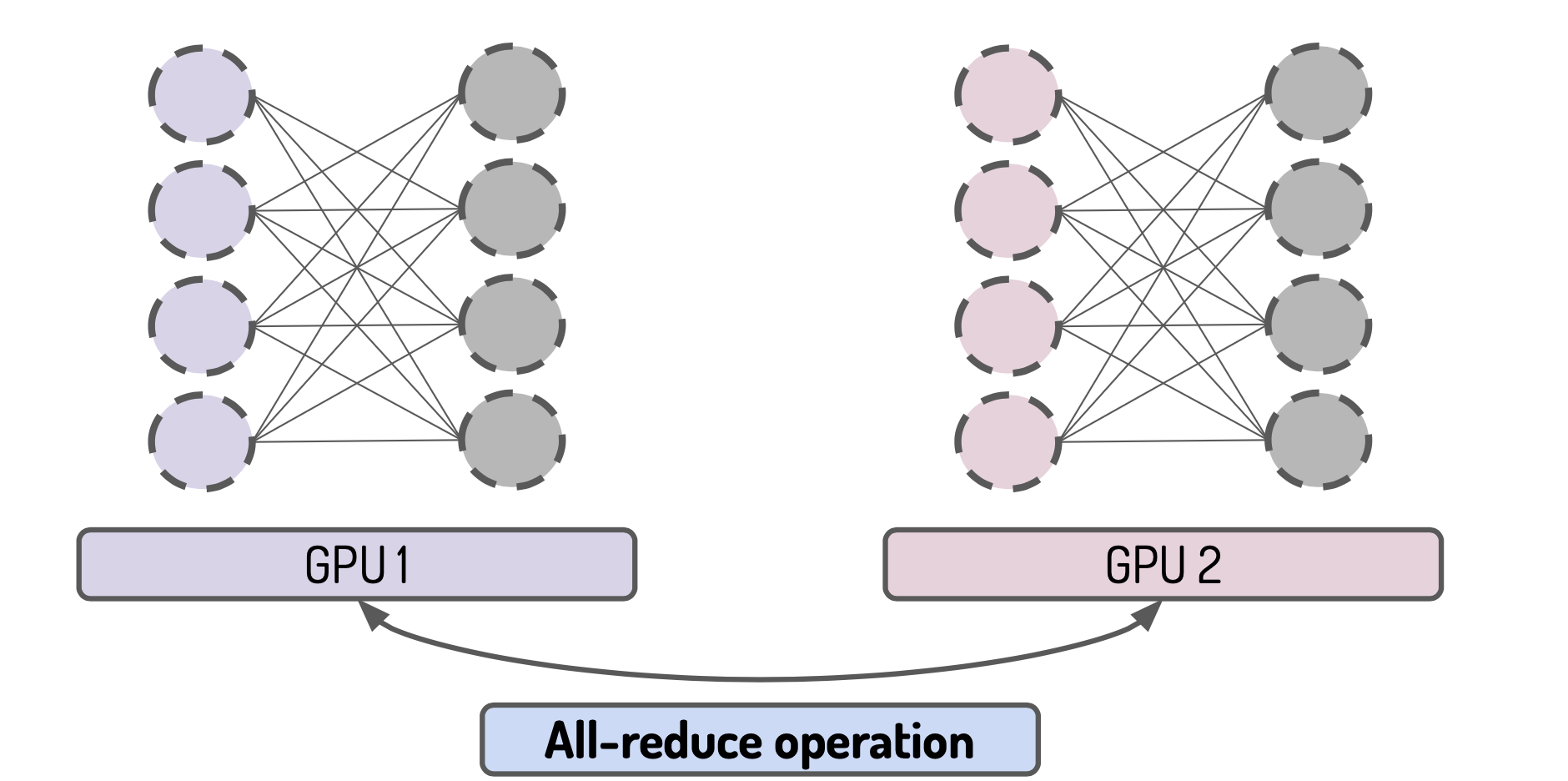
AllReduce is an operation that reduces the target arrays in all processes to a single array and returns the resultant array to all processes.
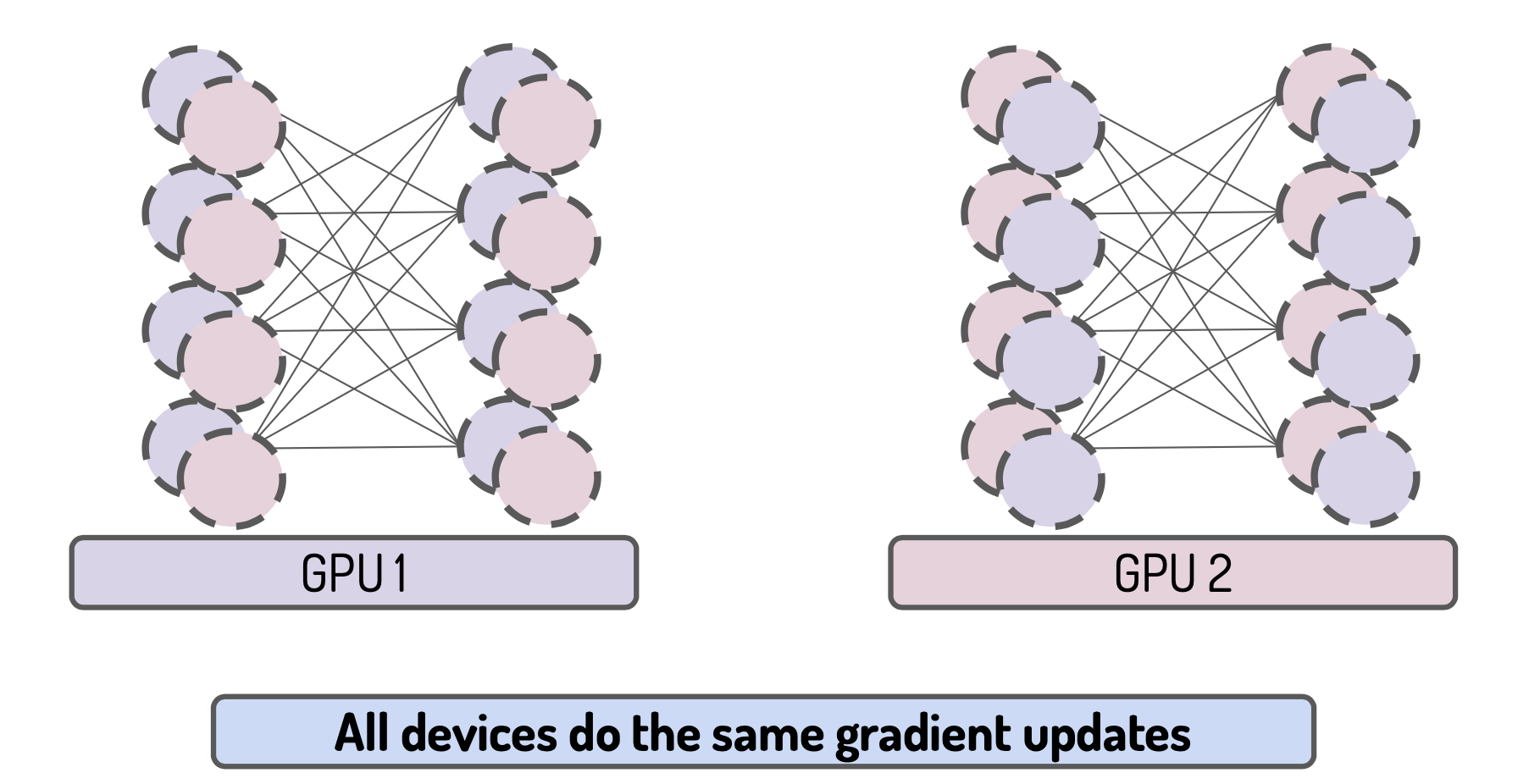
Fifth all replicated model on every devices are updates with the same gradients:
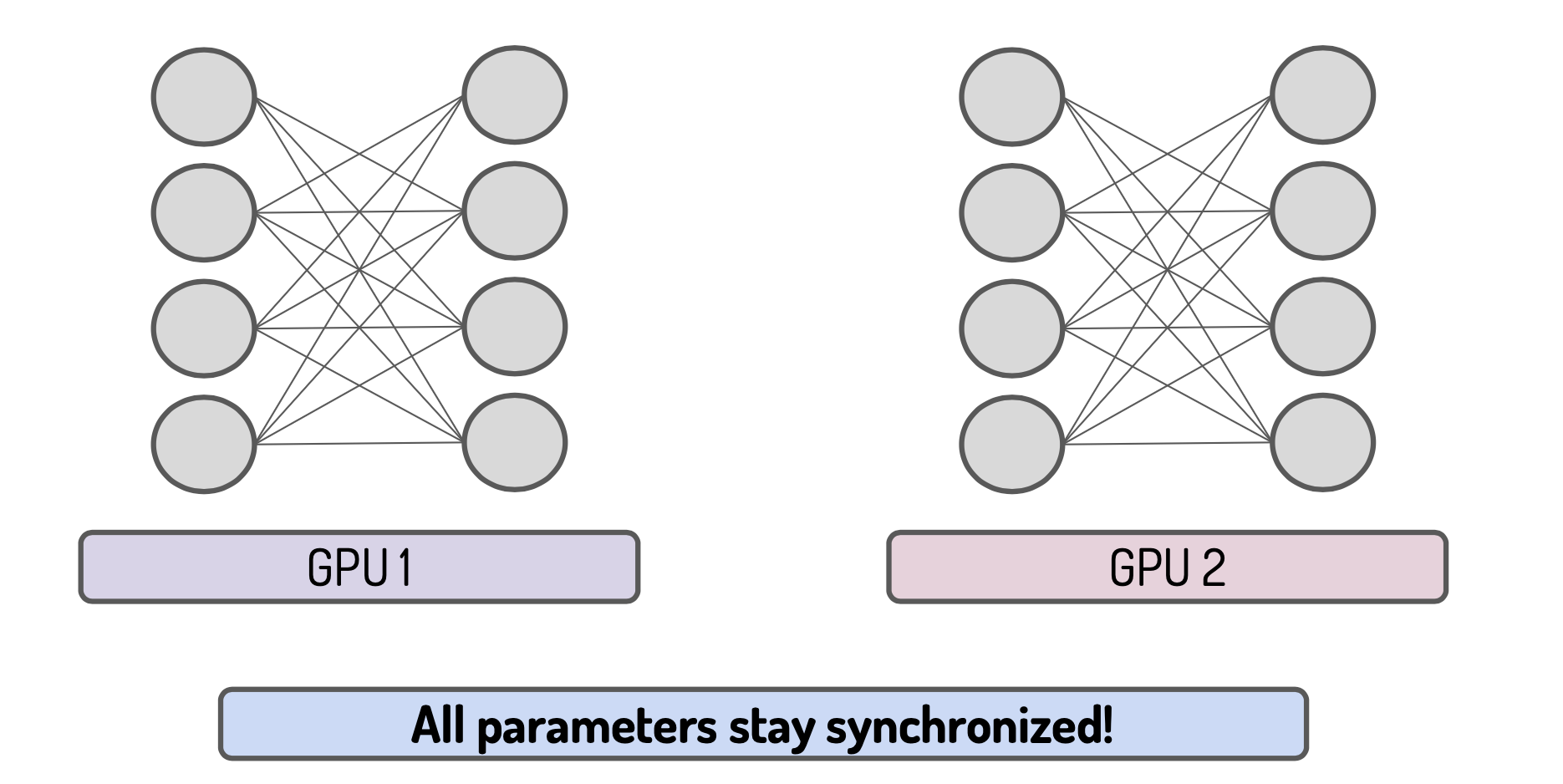
Finally the parameters stay synchronized:
How to split the model across different devices during training:
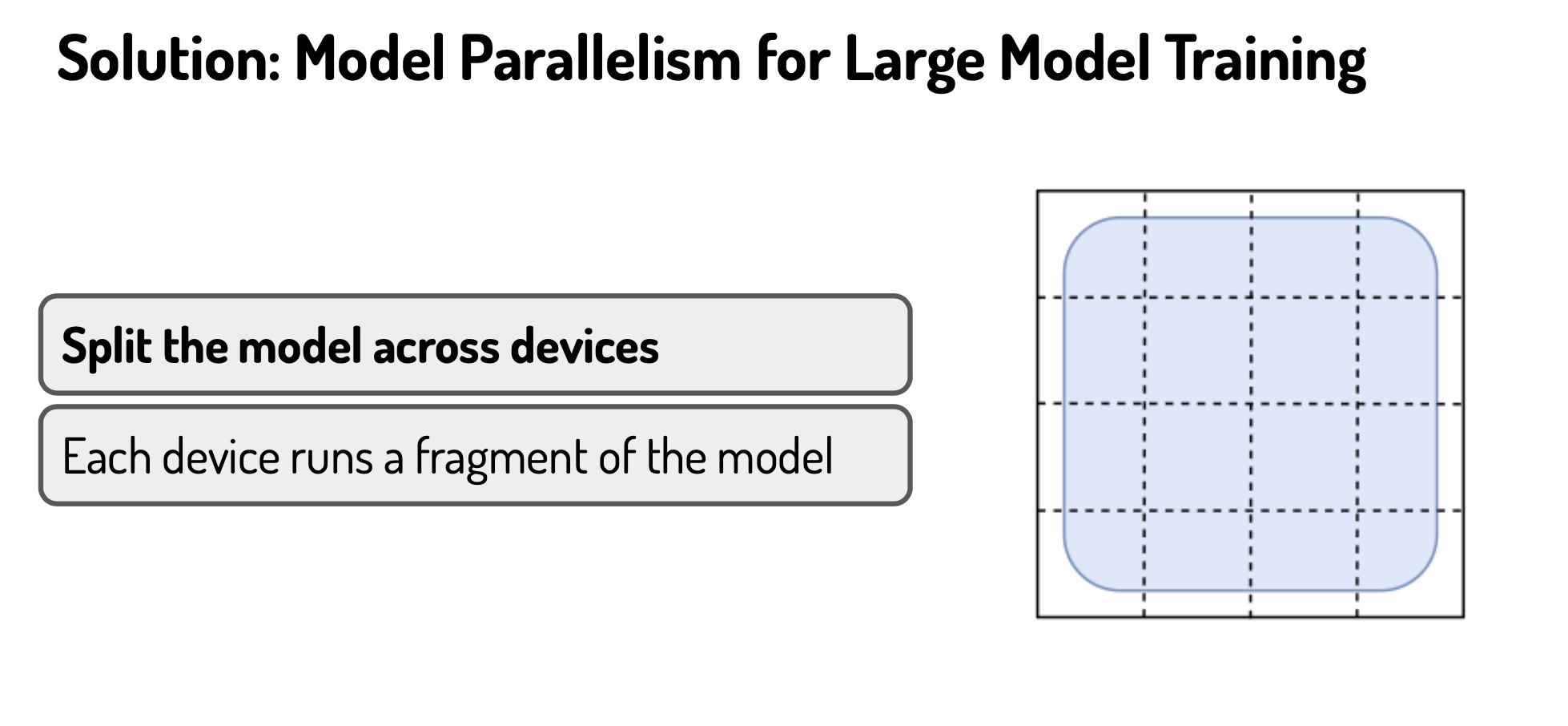
For example, we have 10 GPUs and we want to train a simple ResNet50 model. We could assign the first 5 layers to GPU \(1\), the second 5 layers to GPU \(2\), and so on, and the last 5 layers to GPU \(10\). During the training, in each iteration, the forward propagation has to be done in GPU \(1\) first. GPU \(2\) is waiting for the output from GPU \(#1\), GPU \(3\) is waiting for the output from GPU \(2\), etc. Once the forward propagation is done. We calculate the gradients for the last layers which reside in GPU \(#10\) and update the model parameters for those layers in GPU \(10\). Then the gradients back propagate to the previous layers in GPU \(9\), etc. Each GPU/node is like a compartment in the factory production line, it waits for the products from its previous compartment and sends its own products to the next compartment. True model parallelism means your model is split in such a way that each part can be evaluated concurrently, i.e. the order does NOT matter.

Pipeline parallelism splits the input minibatch into multiple microbatches and pipelines the execution of these microbatches across multiple GPUs
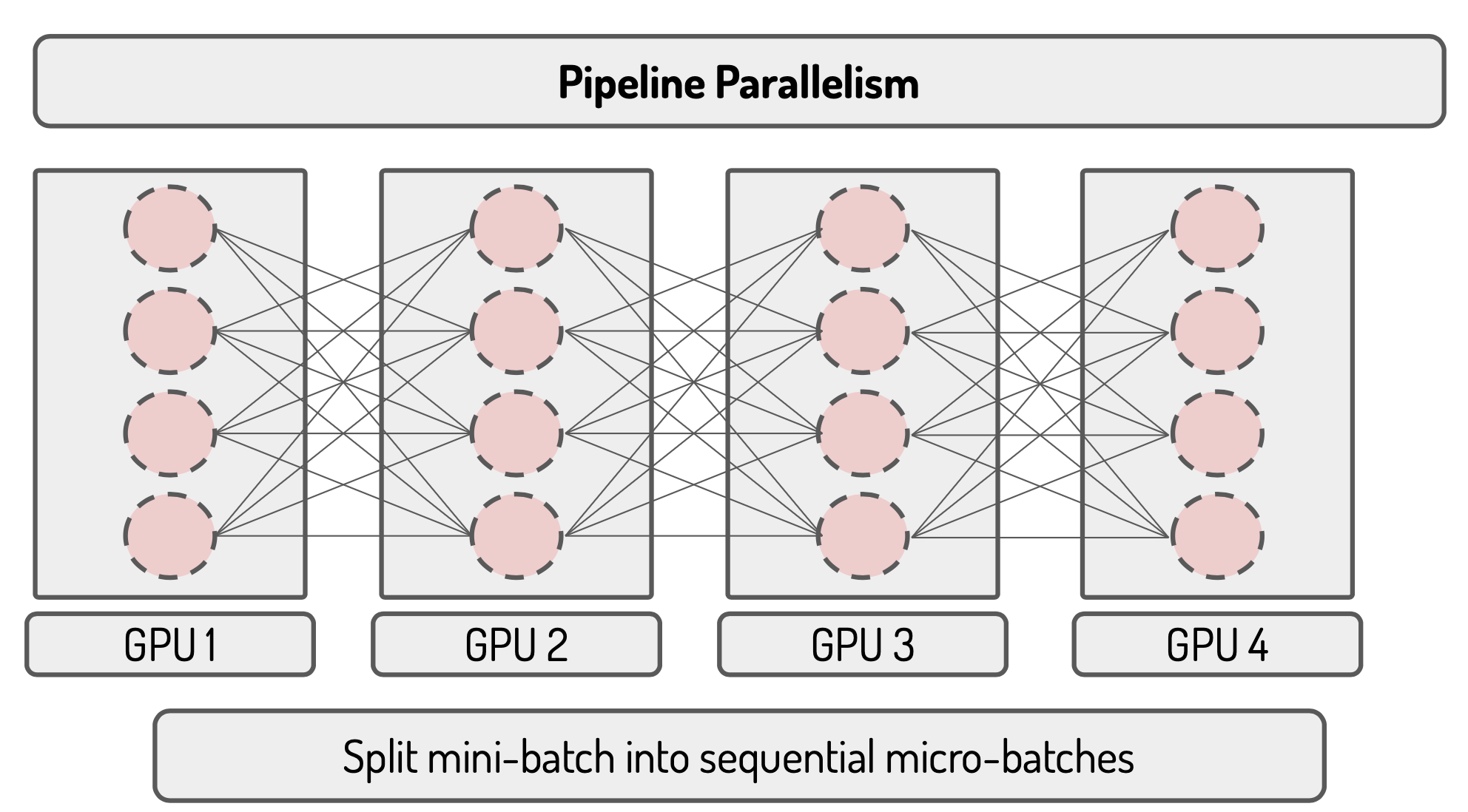
Micro-batch 0 first passes to device 0 and compute by forward function at device 0.
Device 1 receives micro-batch 0 from device 0, computes and transfers it to device 2. At the same time, micro-batch 1 passes to device 0.
Device 2 receives micro-batch 0 from device 1, computes and transfers it to device 3. At the same time, device 1 receives micro-batch 1 from device 0 computes and transfers it to device 2. At the same time, micro-batch 2 passes to device 0.
Device 3 receives micro-batch 0 from device 2, computes and transfers it to device 4. Device 2 receives micro-batch 1from device 1, computes and transfers it to device 3. At the same time, device 1 receives micro-batch 2 from device 0, computes and transfers it to device 2. At the same time, micro-batch 3 passes to device 0.
See: