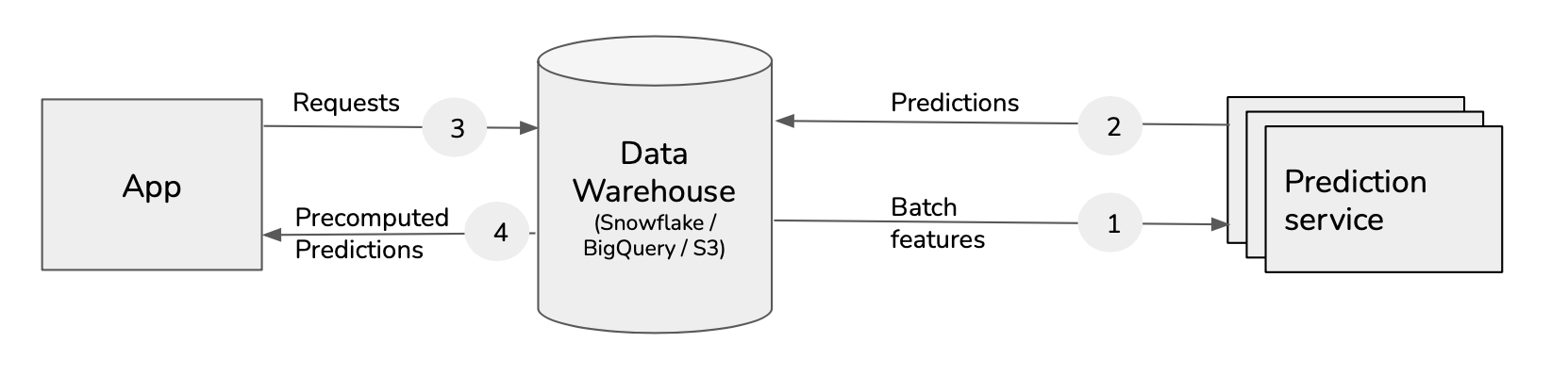
Different architectures exist: using API, databases or brokers:
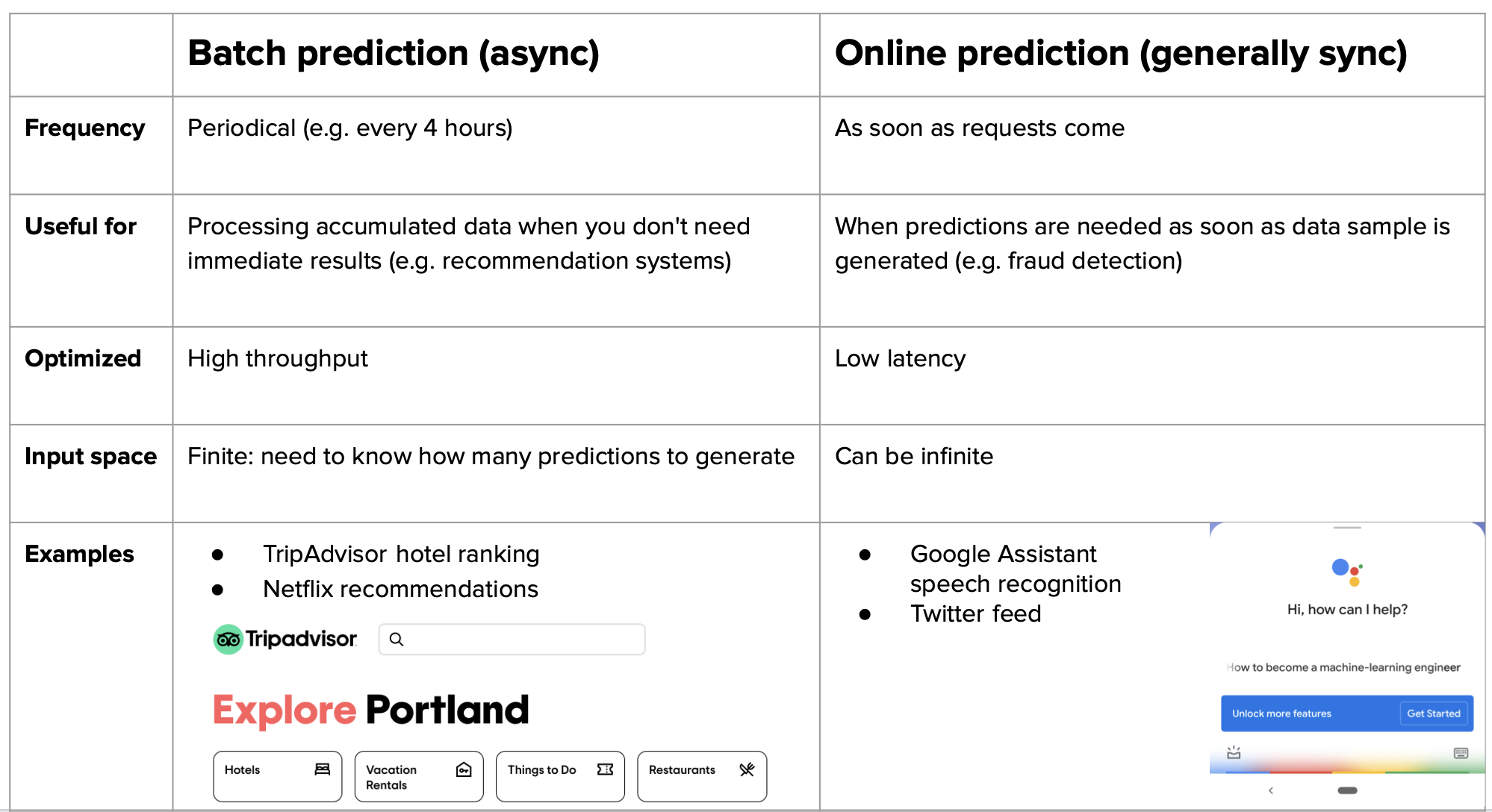
To perform online prediction, an ML system requires two key elements:
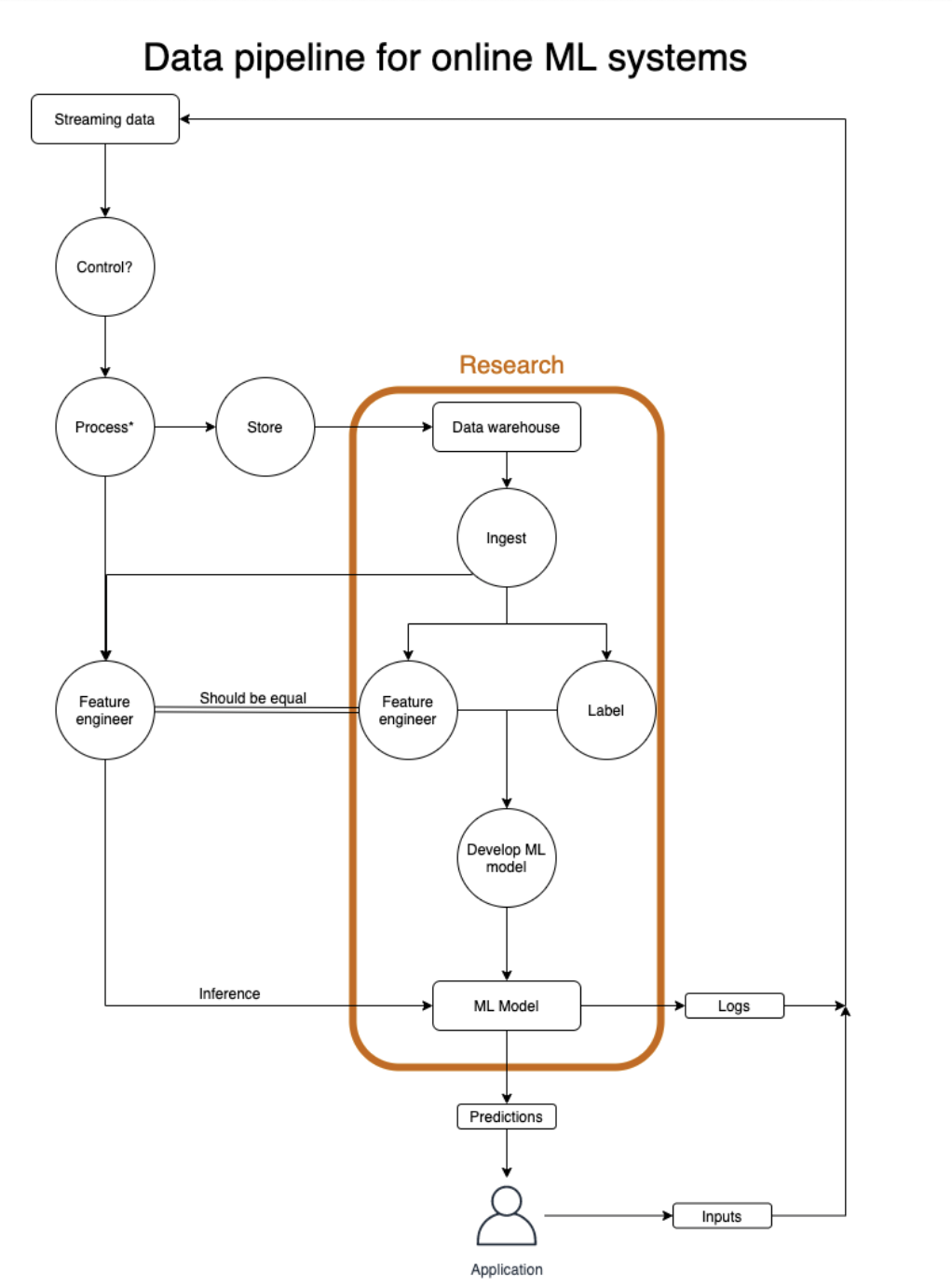
Stream processing is a concept that enables us to build ML systems (pipelines) that can respond in real-time and near real-time.
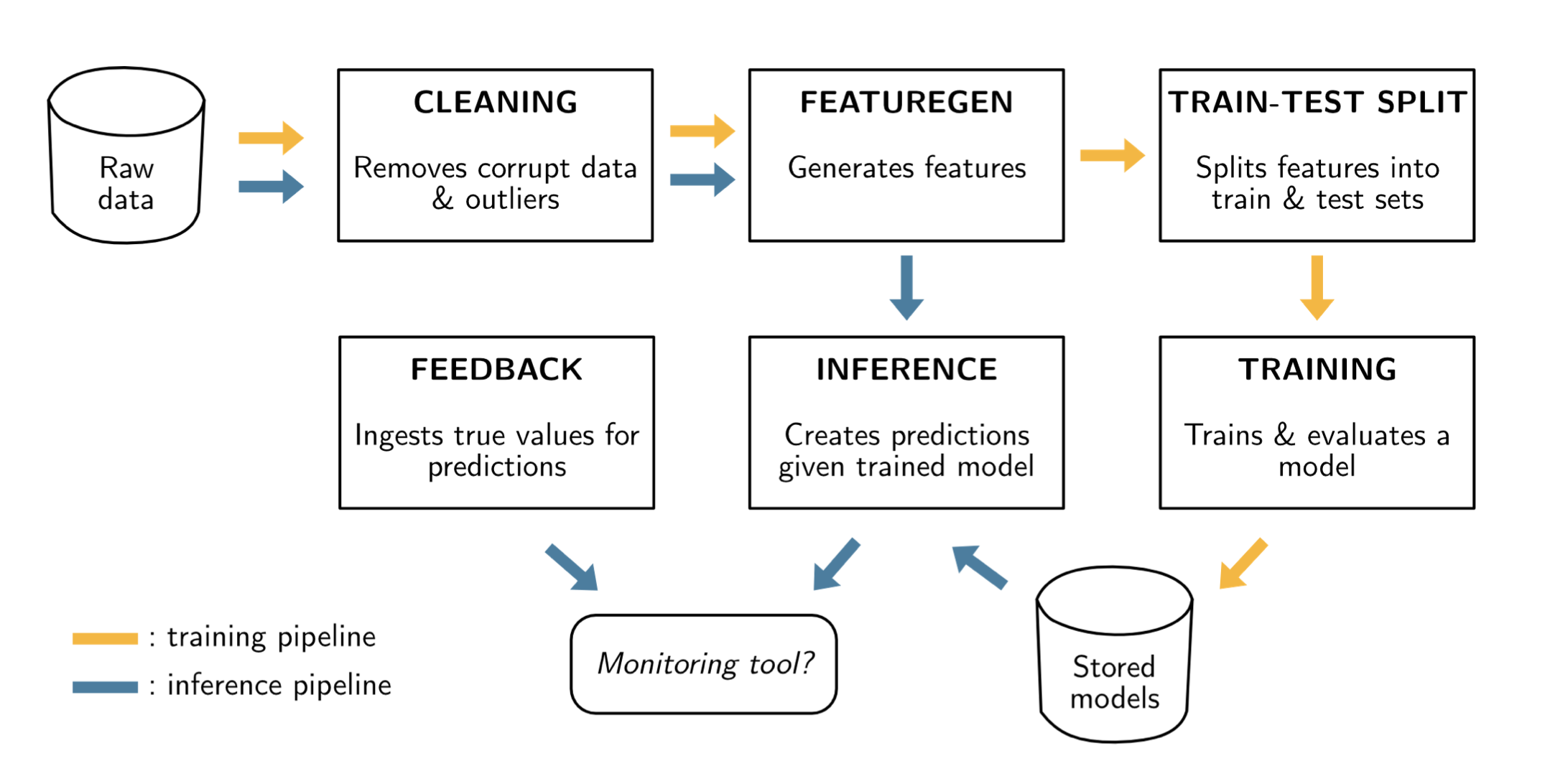
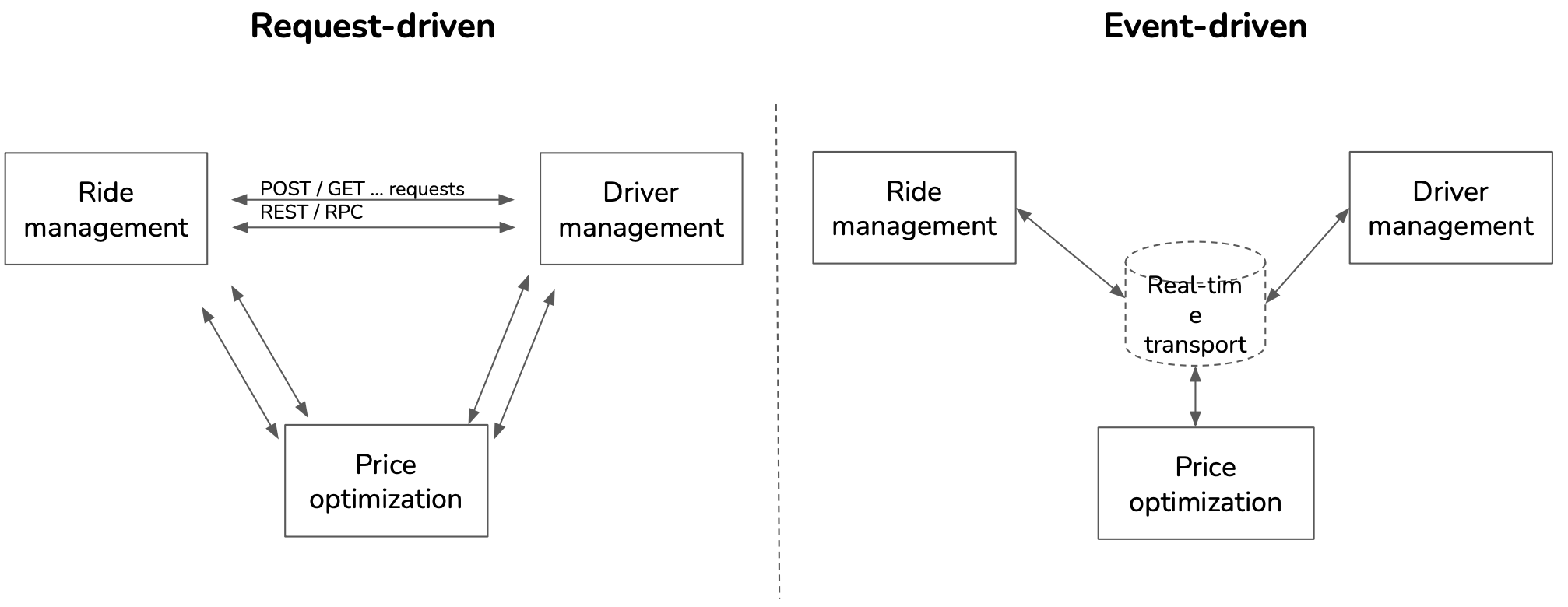
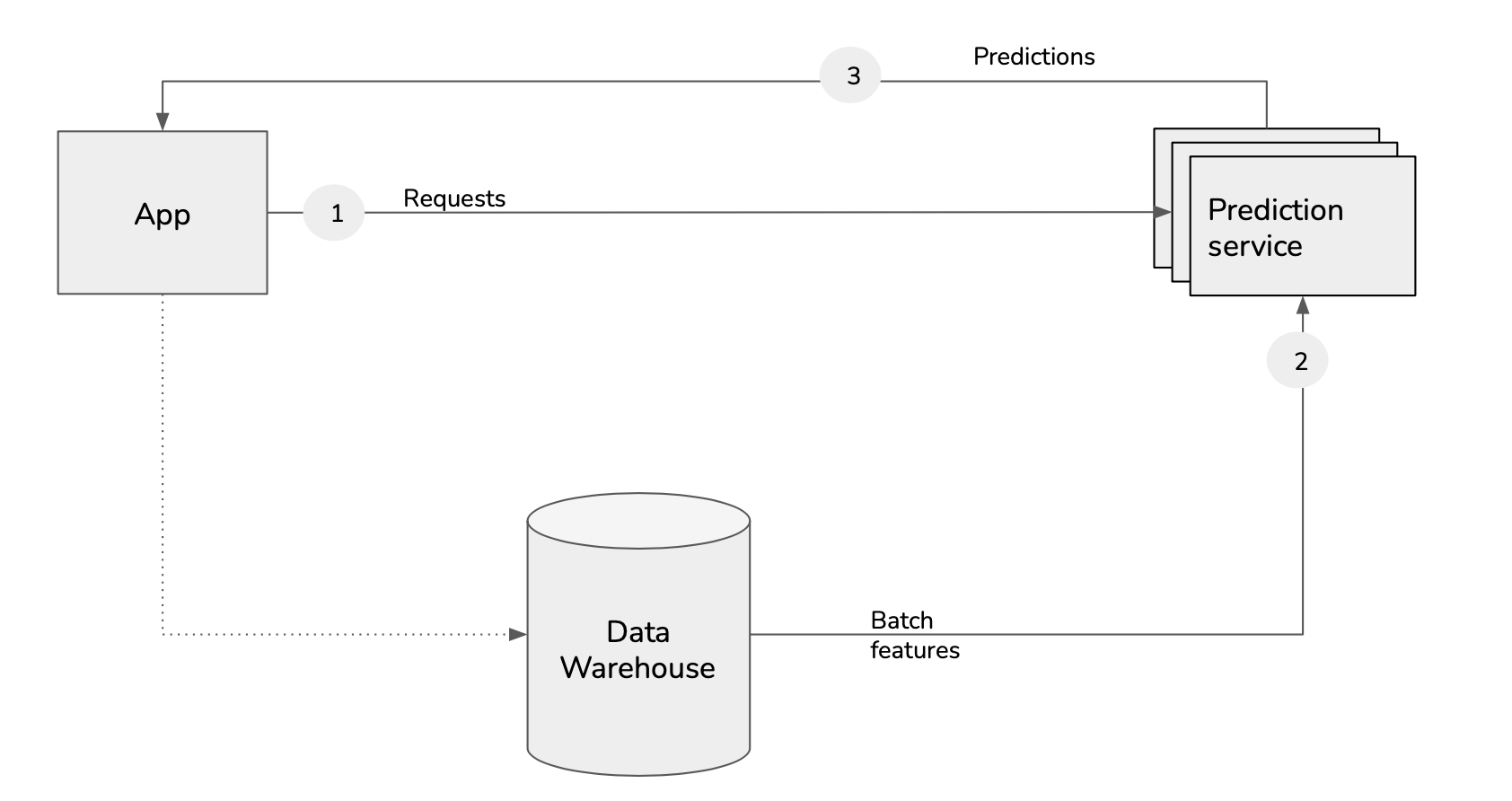
A ride-sharing application is composed of 3 parts that need to exchange data:
Different architectures exist: using API, databases or brokers:
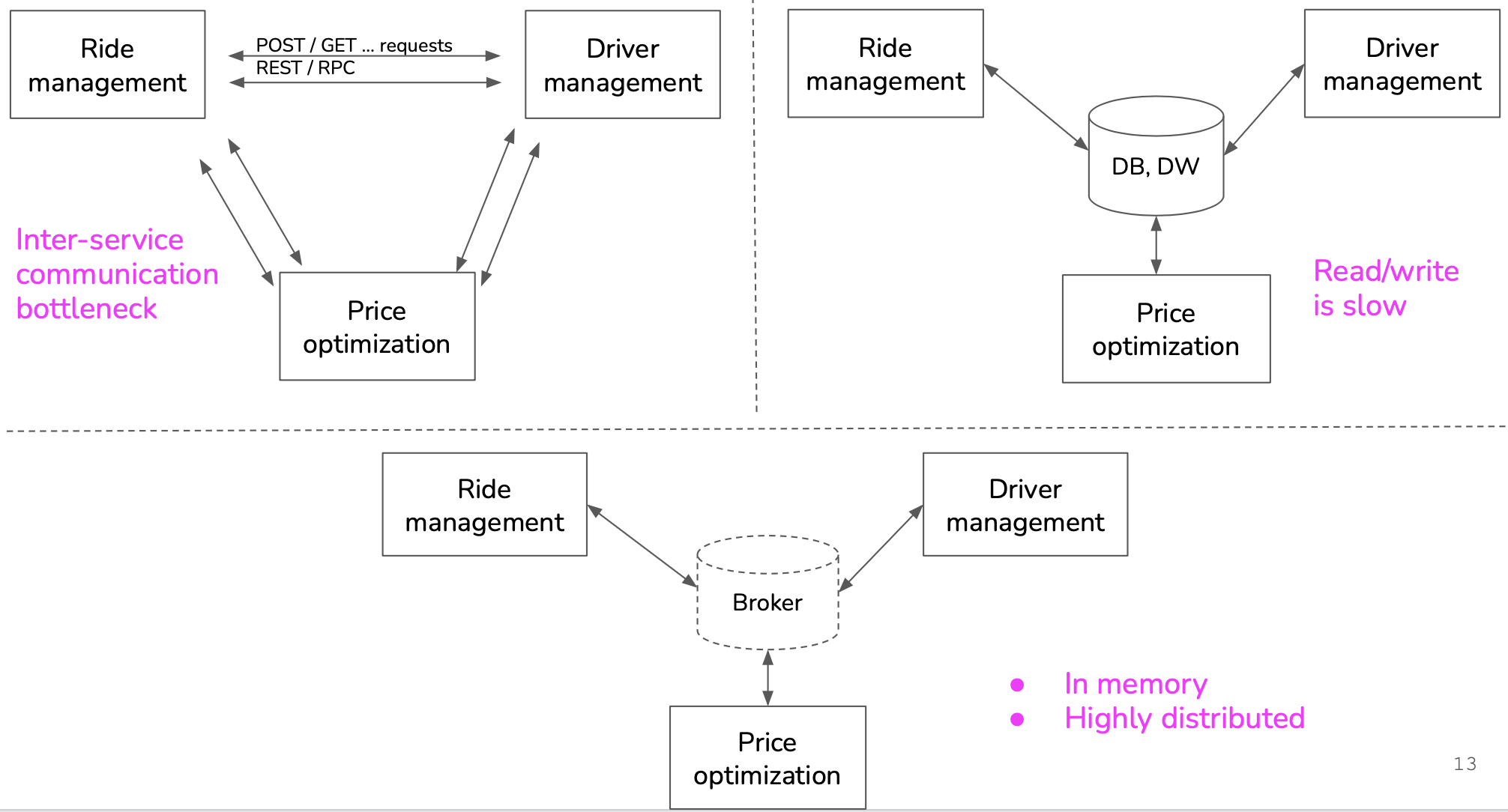
A Broker or Service Broker implements native in-database asynchronous message processing functionalities. It monitors the completion of tasks, usually command messages, between two different applications in the database engine. It is responsible for the safe delivery of messages from one end to another.
When two applications (within or outside of SQL Server) communicate, neither can access the technical details at the opposite end. It is the job of Service Broker to protect sensitive messages and reliably deliver them to the designated location. Service Broker is highly integrated and provides a simple Transact-SQL interface for sending and receiving messages, combined with a set of strong guarantees for message delivery and processing.
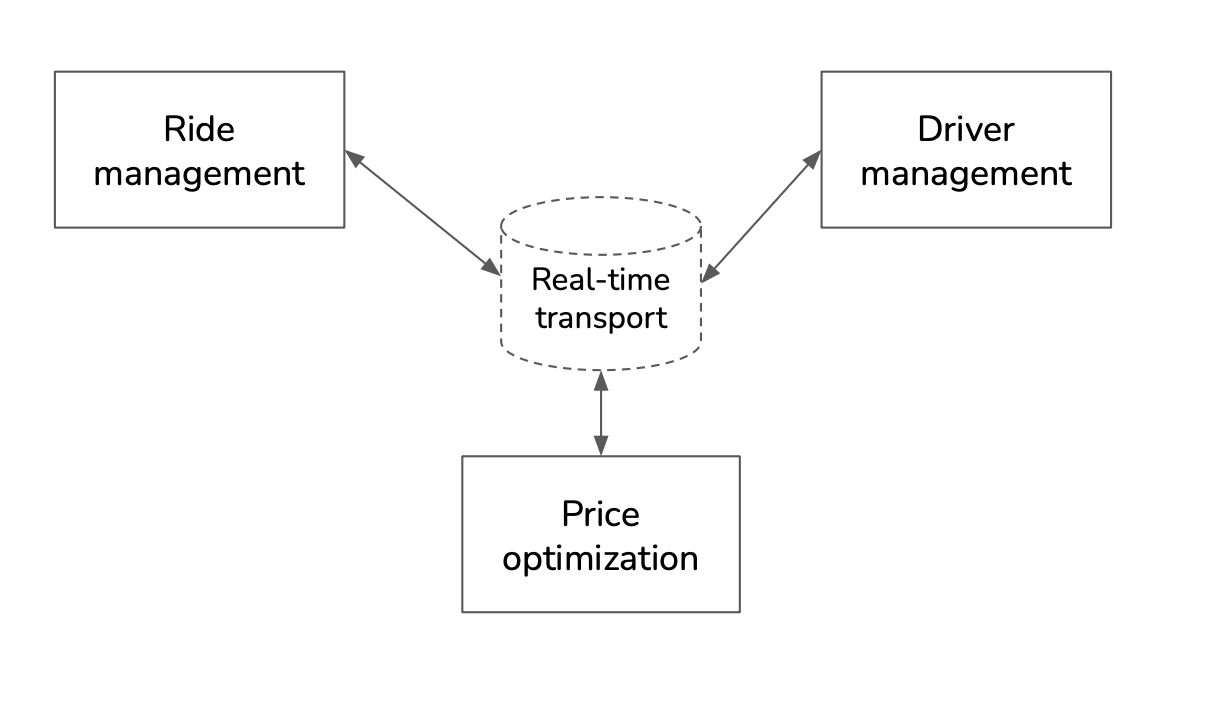
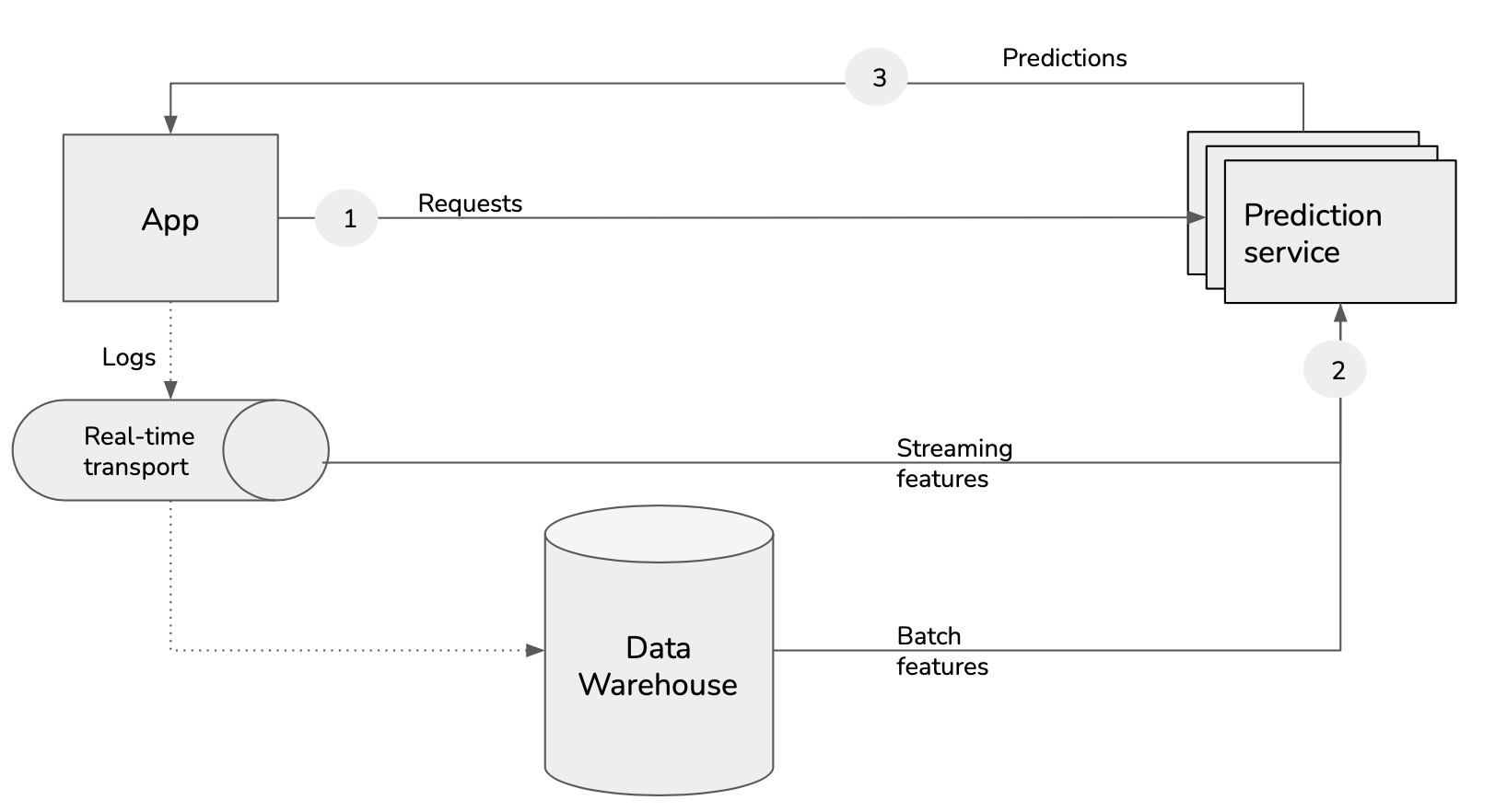
A broker is a real-time transport solution.


See:
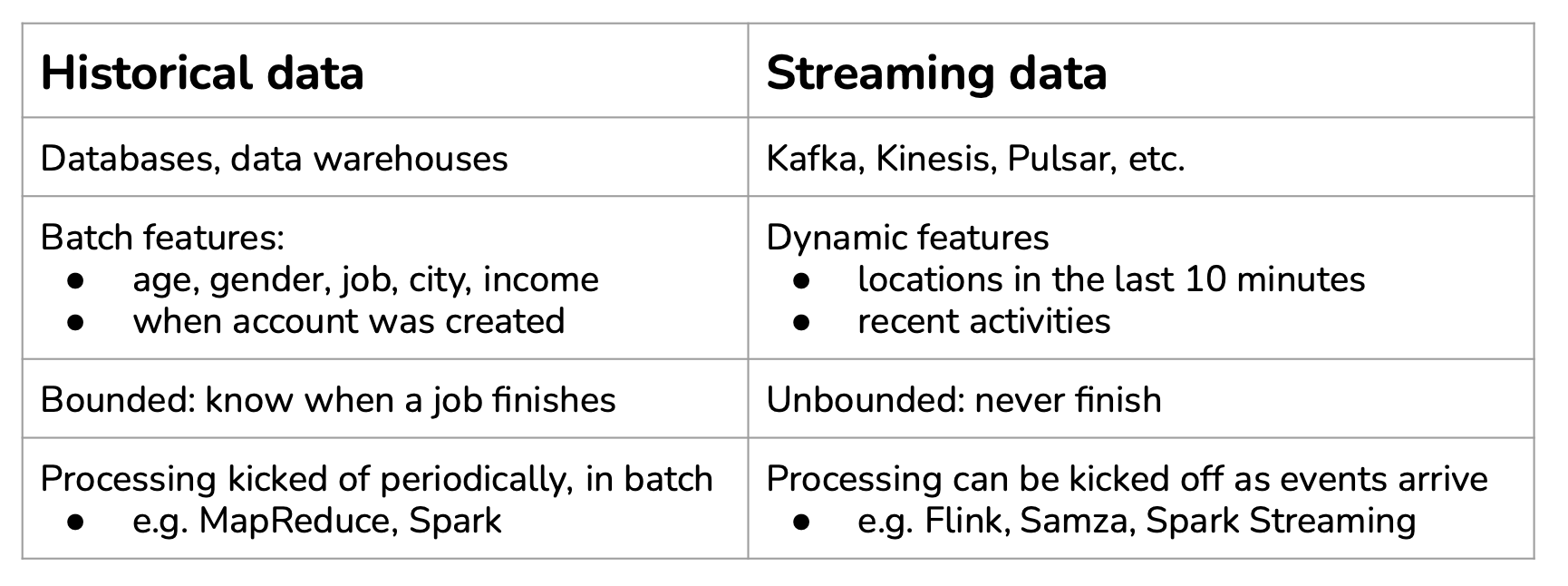

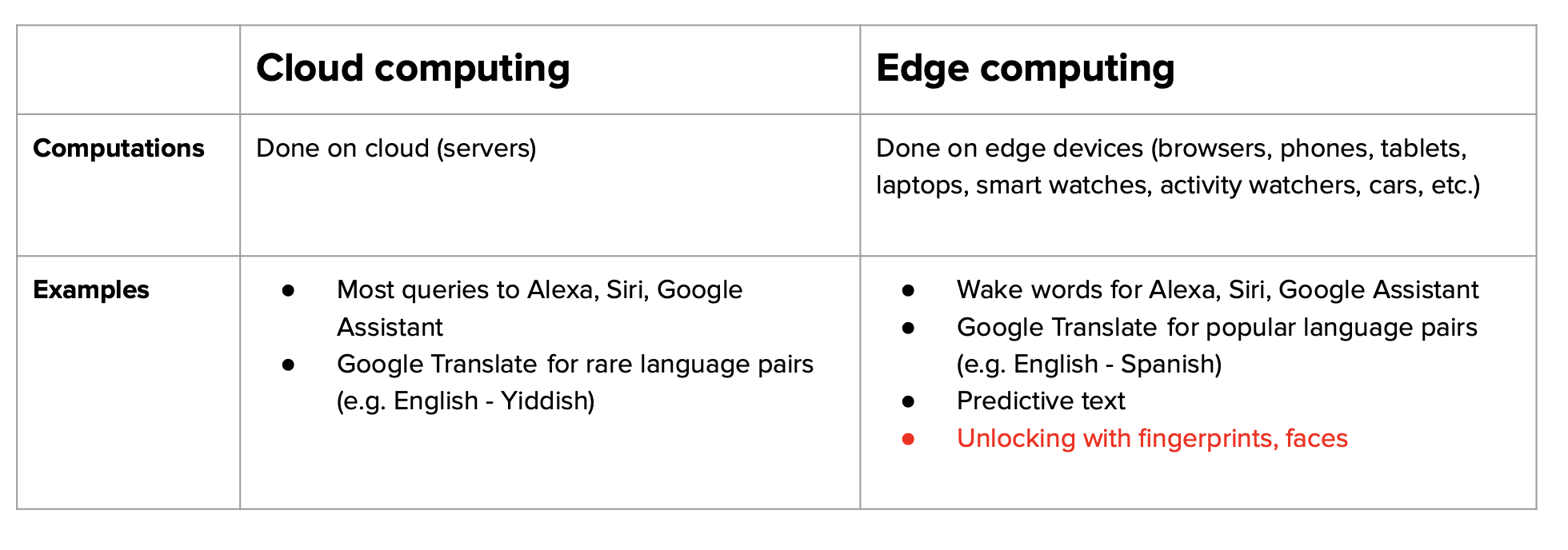
Here is a comparison of both methods:
HTTP protocol:
Streaming:
Cloud computing means a large chunk of computation is done on the cloud, either public clouds or private clouds.
Edge computing means a large chunk of computation is done on the consumer devices
Benefits:
Challenges of ML on the edge:
Solutions:
Solution to speed up model inference:
Reduces the size of a model by using fewer bits to represent parameter values:
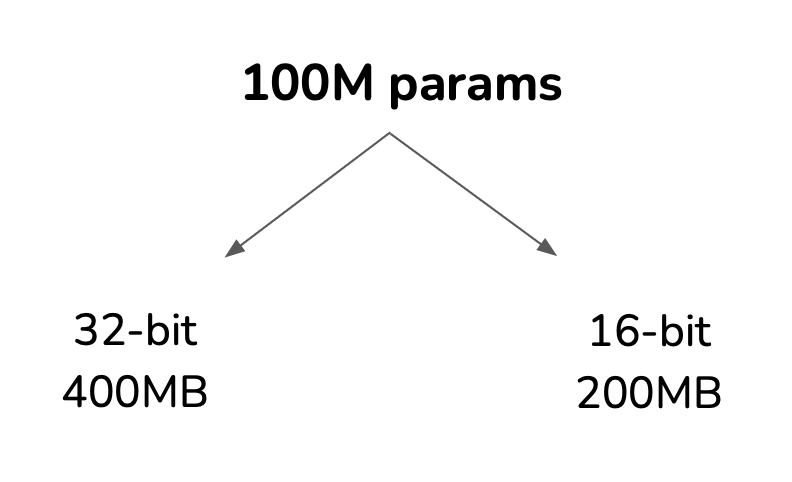
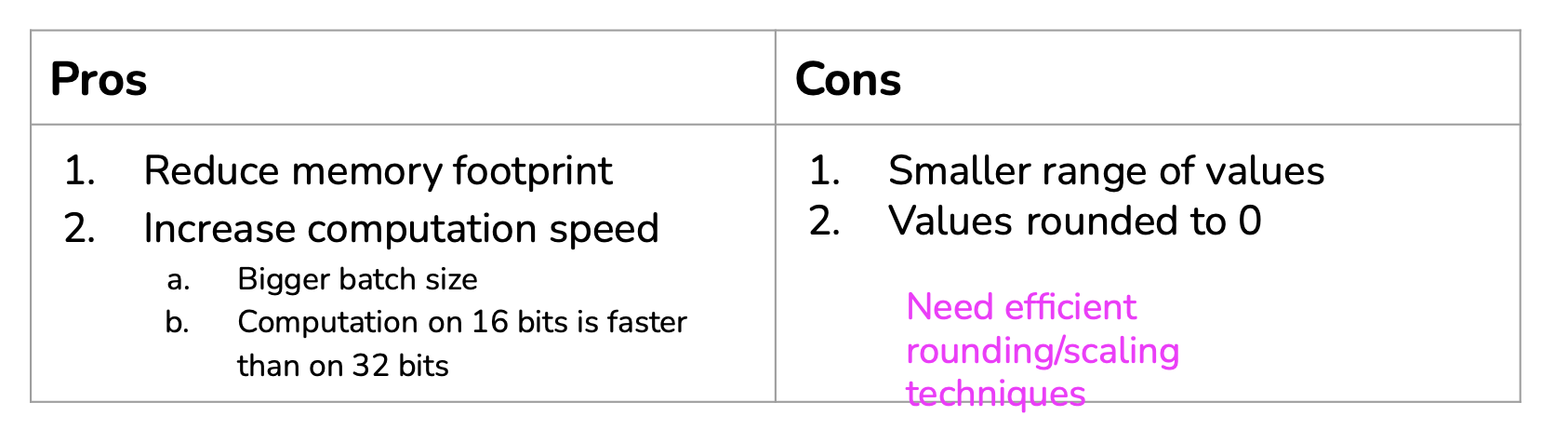
Post-training quantization:

Train a small model (“student”) to mimic the results of a larger model (“teacher”):
Pros:
Cons:
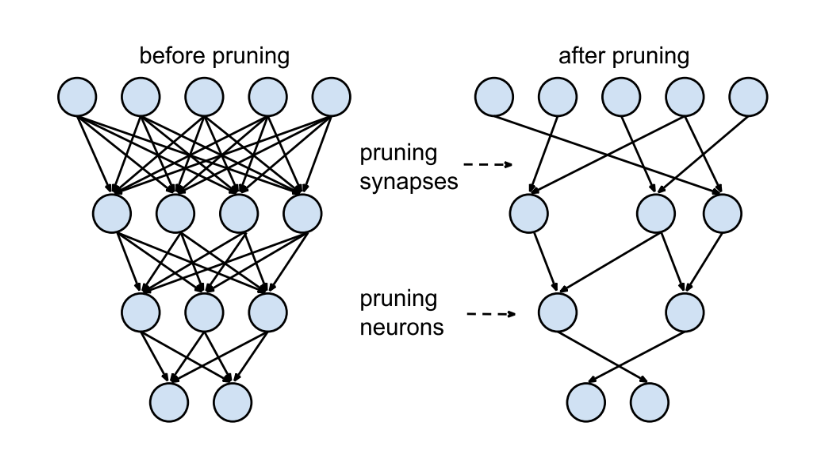

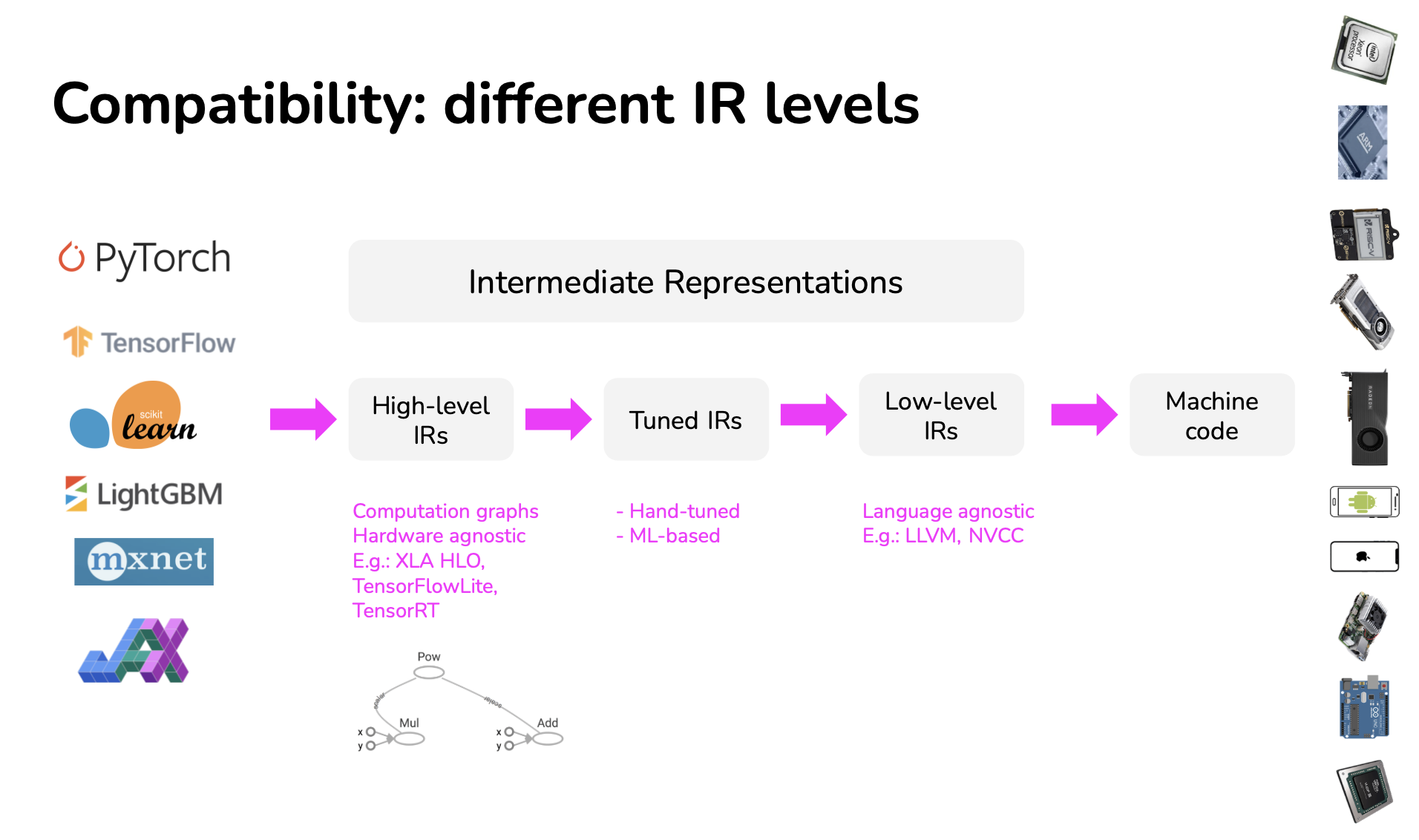
Framework developers tend to focus on providing support to only a handful of server-class hardware, and hardware vendors tend to offer their own kernel libraries for a narrow range of frameworks. Deploying ML models to new hardware requires significant manual effort.
Instead of targeting new compilers and libraries for every new hardware backend, what if we create a middle man to bridge frameworks and platforms? Framework developers will no longer have to support every type of hardware, only need to translate their framework code into this middle man. Hardware vendors can then support one middle man instead of multiple frameworks.
This type of “middle man” is called an intermediate representation (IR). IRs lie at the core of how compilers work. This process is also called “lowering”, as in you “lower” your high-level framework code into low-level hardware-native code.
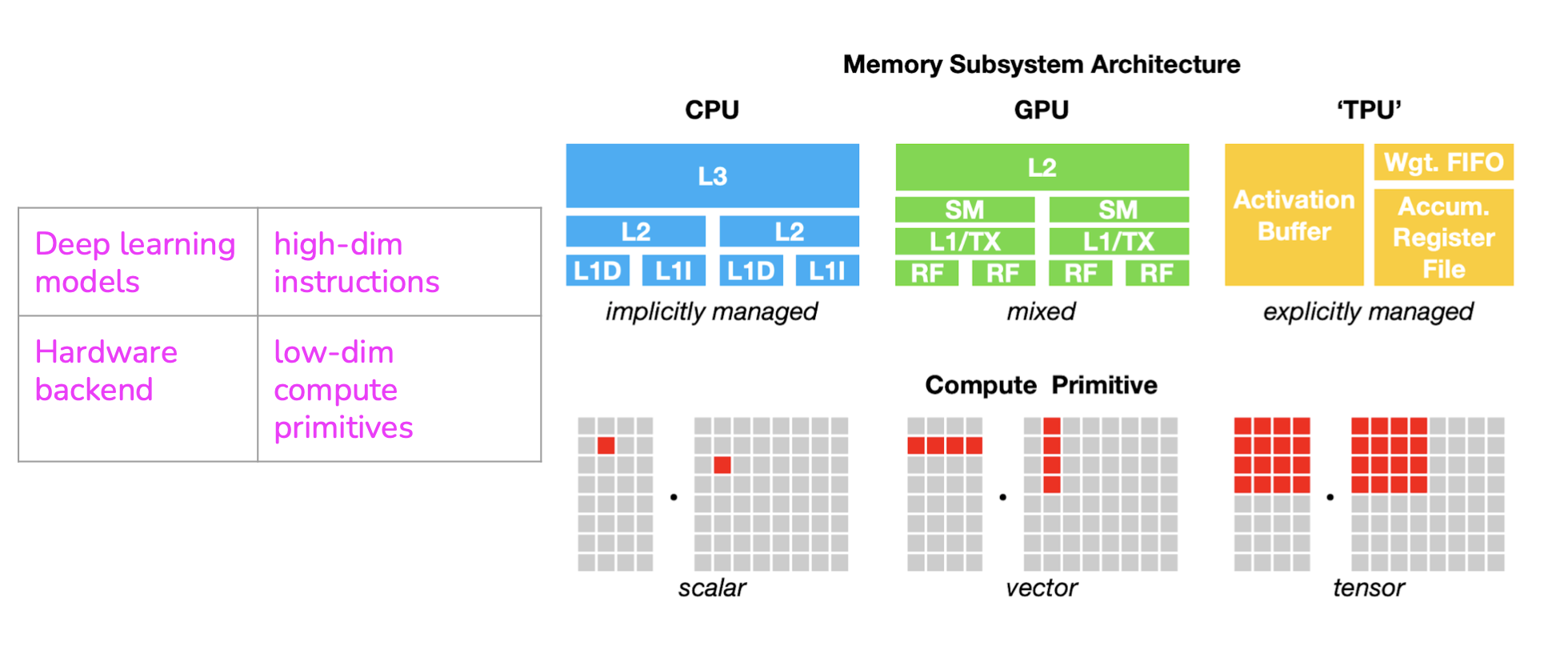
The compute primitive of CPUs used to be a number (scalar), the compute primitive of GPUs used to be a one-dimensional vector, whereas the compute primitive of TPUs is a two-dimensional vector (tensor). Performing a convolution operator will be very different with 1-dimensional vectors compared to 2-dimensional vectors. You’d need to take this into account to use them efficiently.
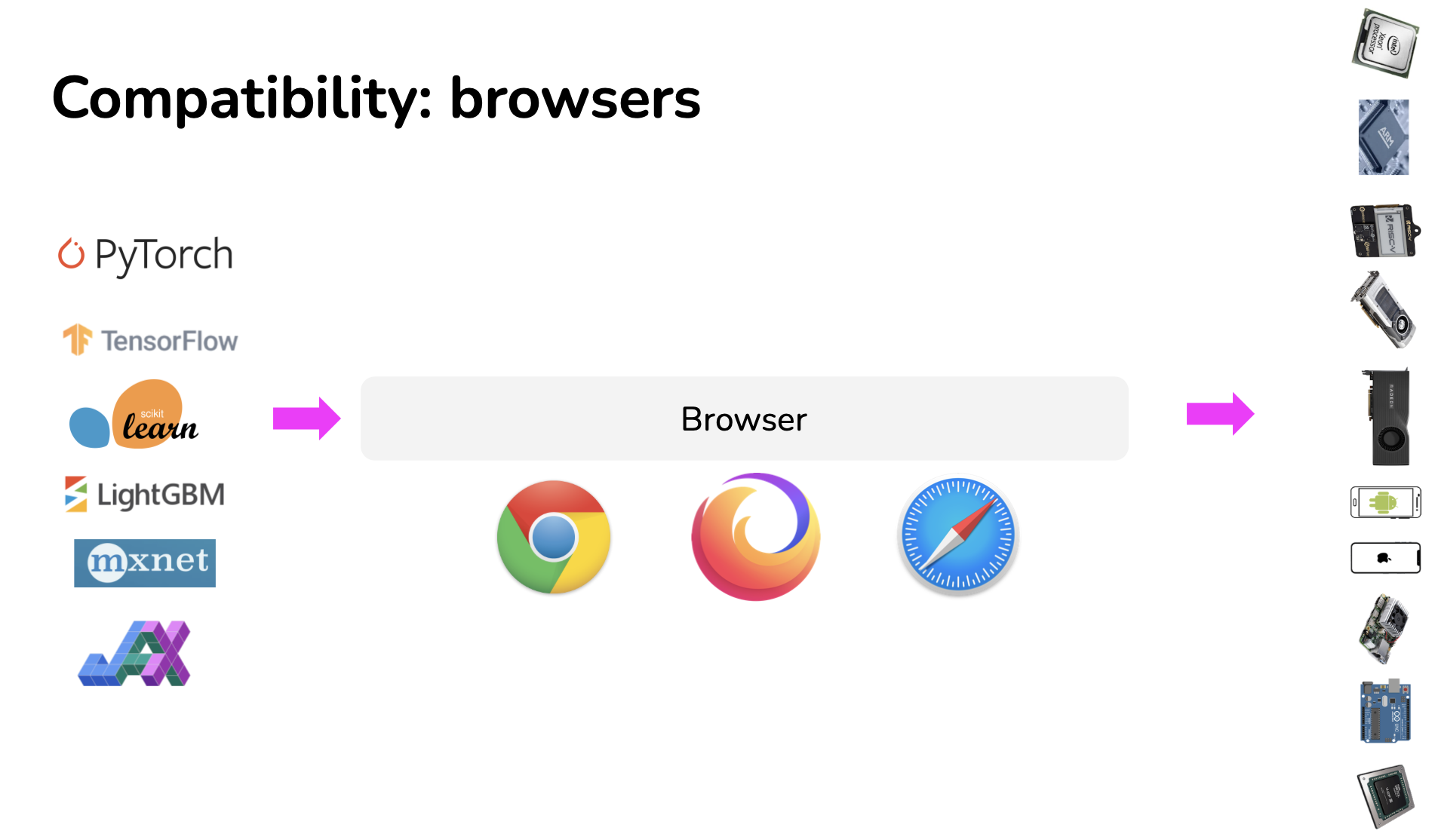
It is possible to generate code that can run on just any hardware backends by running that code in browsers. If you can run your model in a browser, you can run your model on any device that supports browsers: Macbooks, Chromebooks, iPhones, Android phones, and more. You wouldn’t need to care what chips those devices use. If Apple decides to switch from Intel chips to ARM chips, it’s not your problem.
JavaScript:
WebAssembly (WASM):
See: