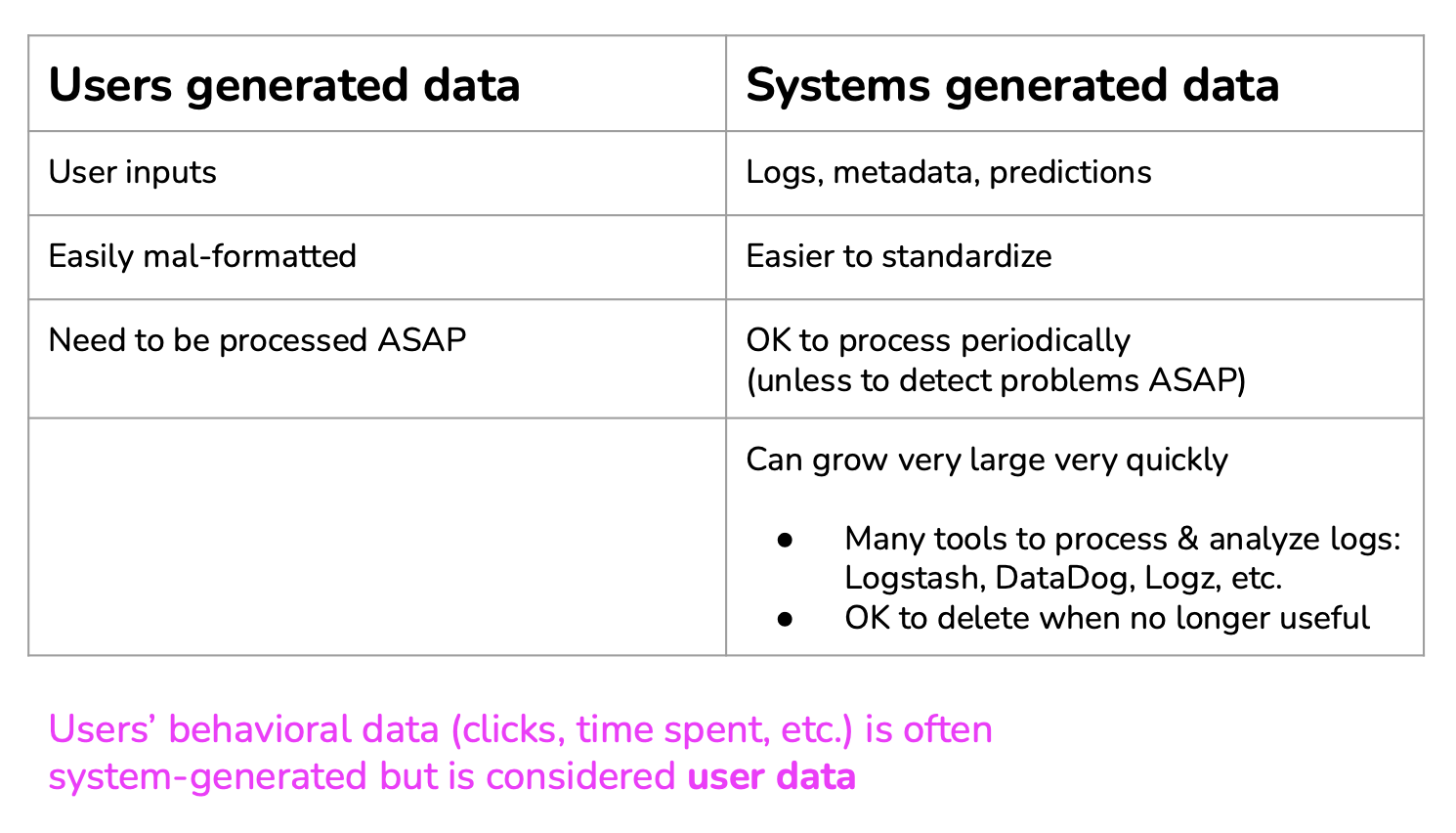
Data can be user generated of systel generated:
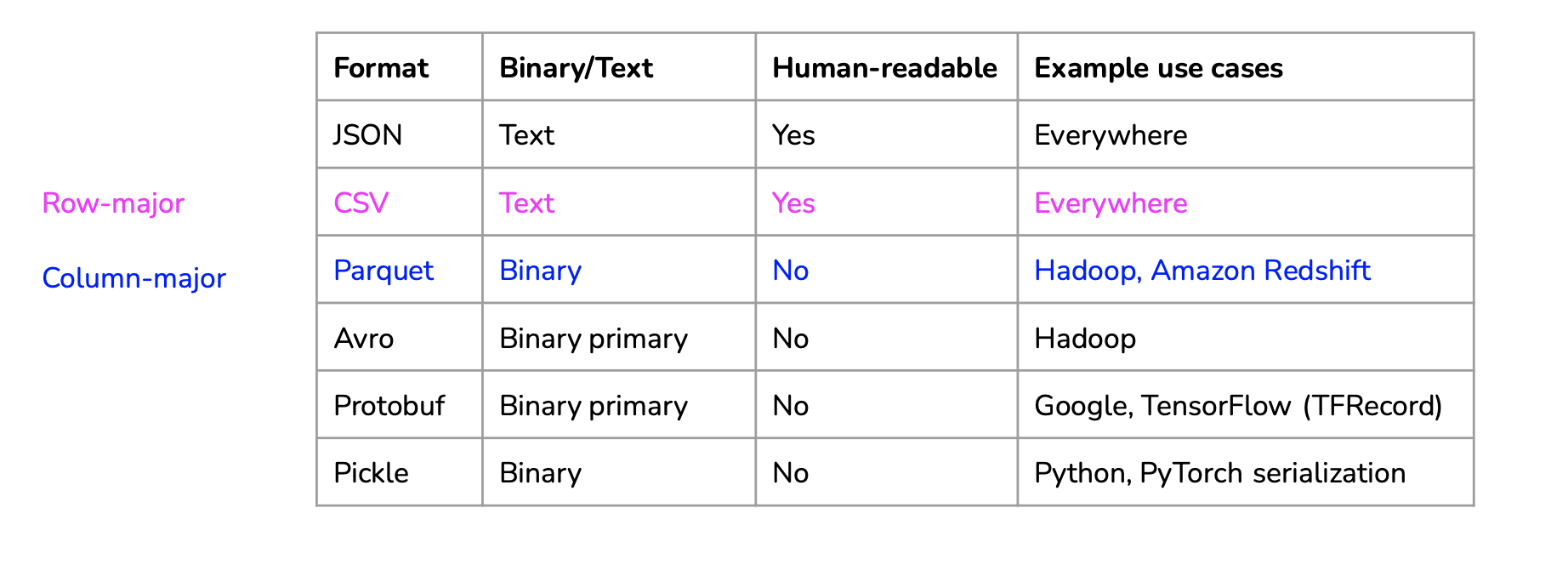
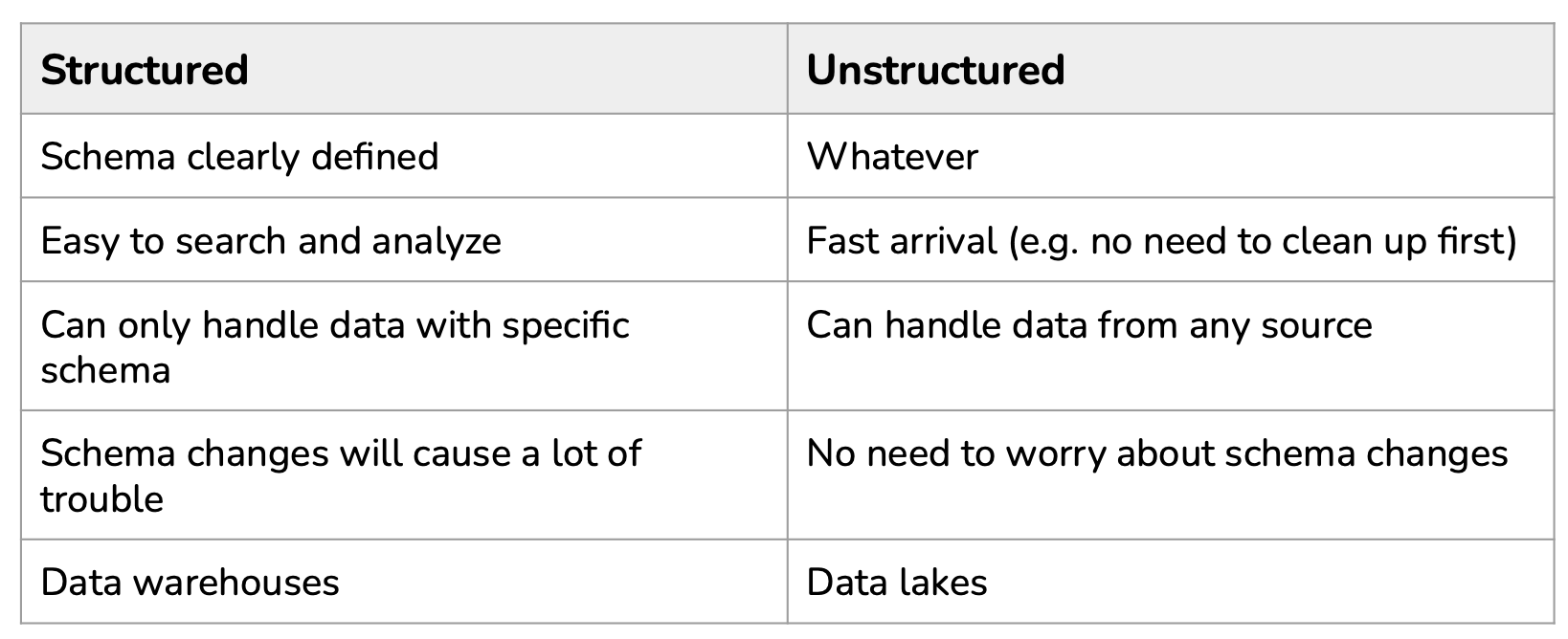
Different data formats exist:
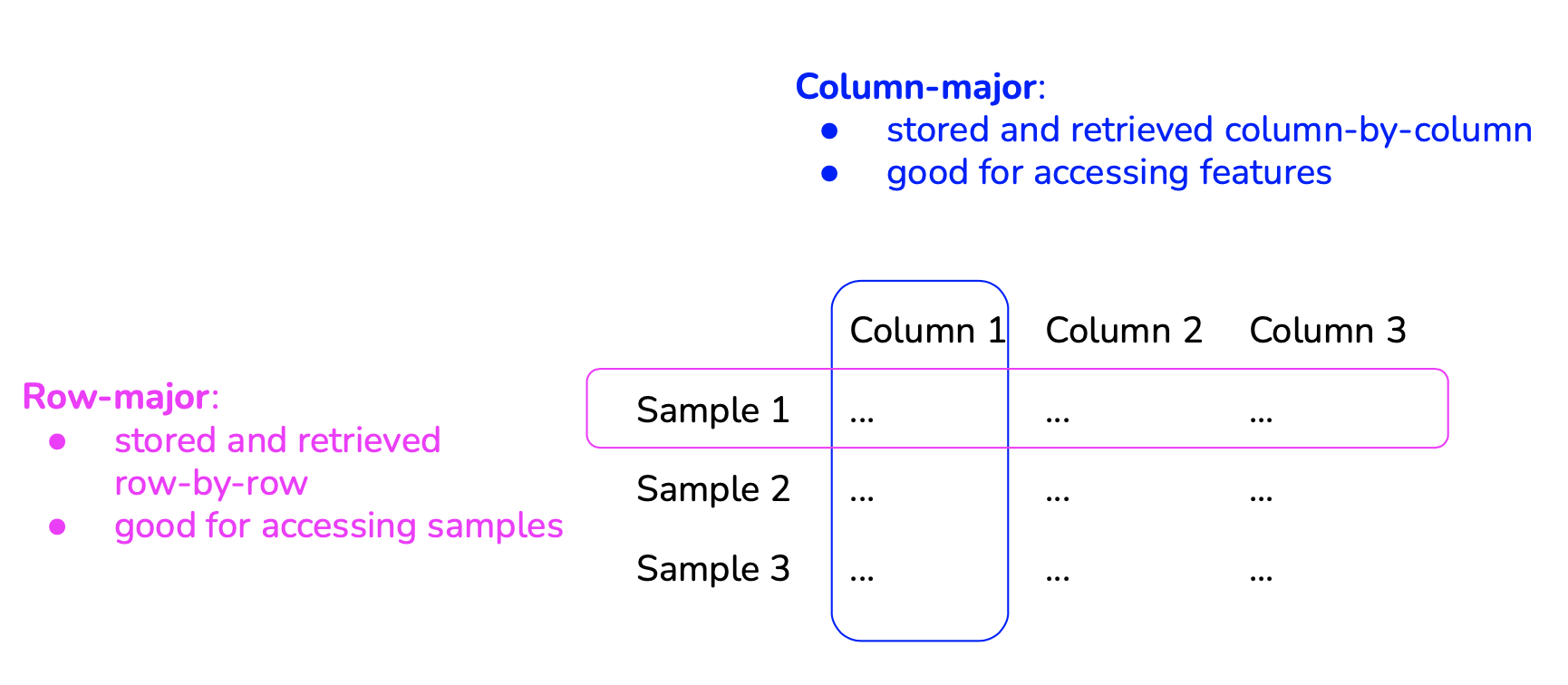
Here is a representation of Row-major vs Column-major data types:
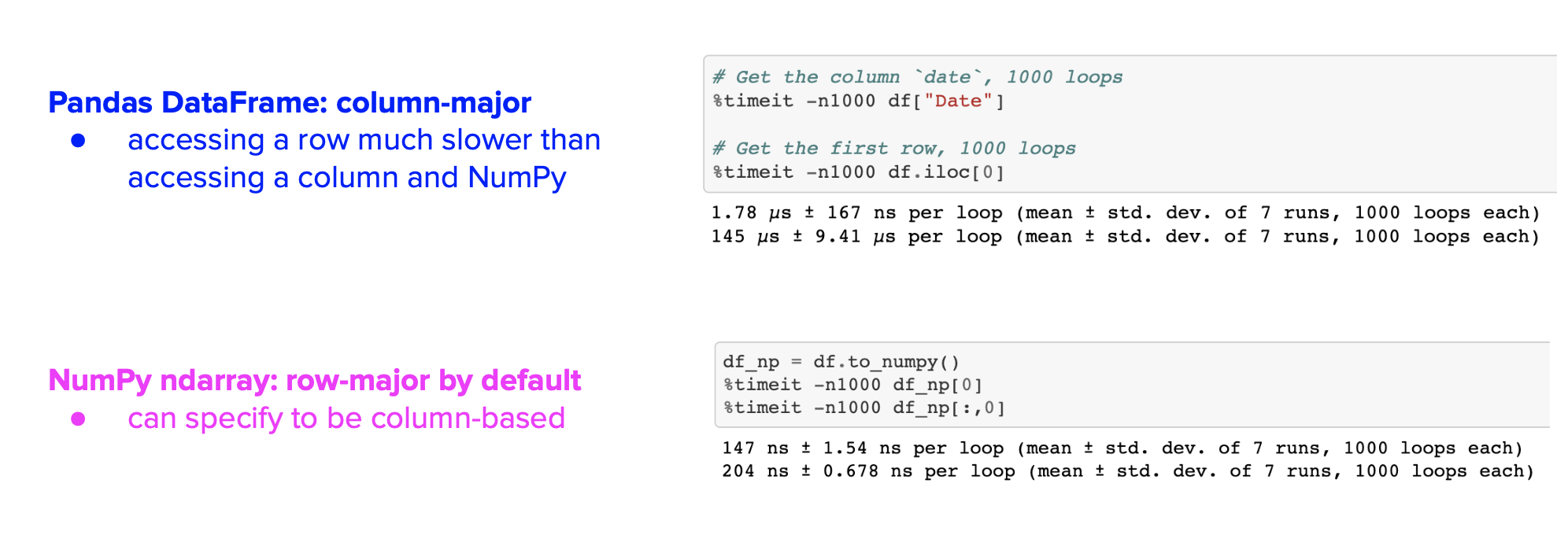
Here is a example of difference in access time:
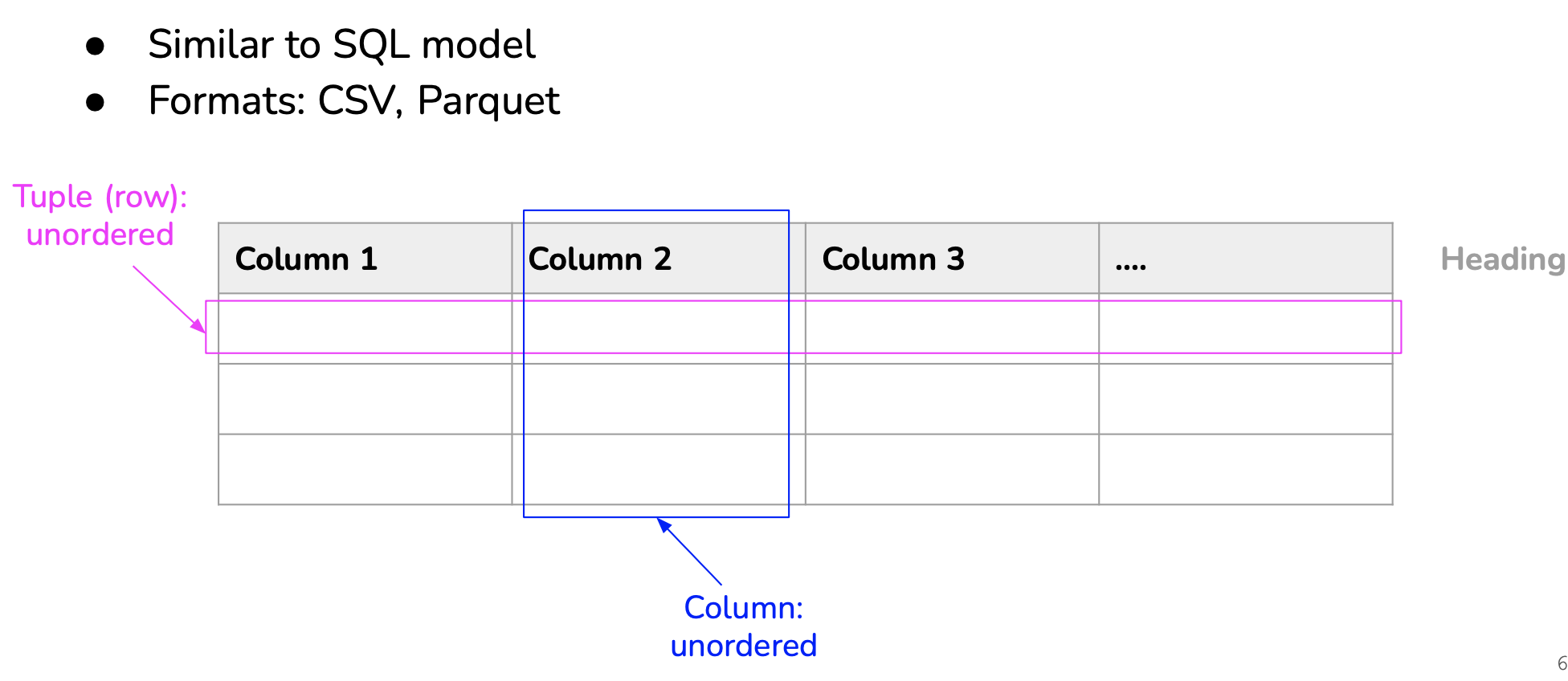
Relational data model can be summarized as ‘data stored in table’:
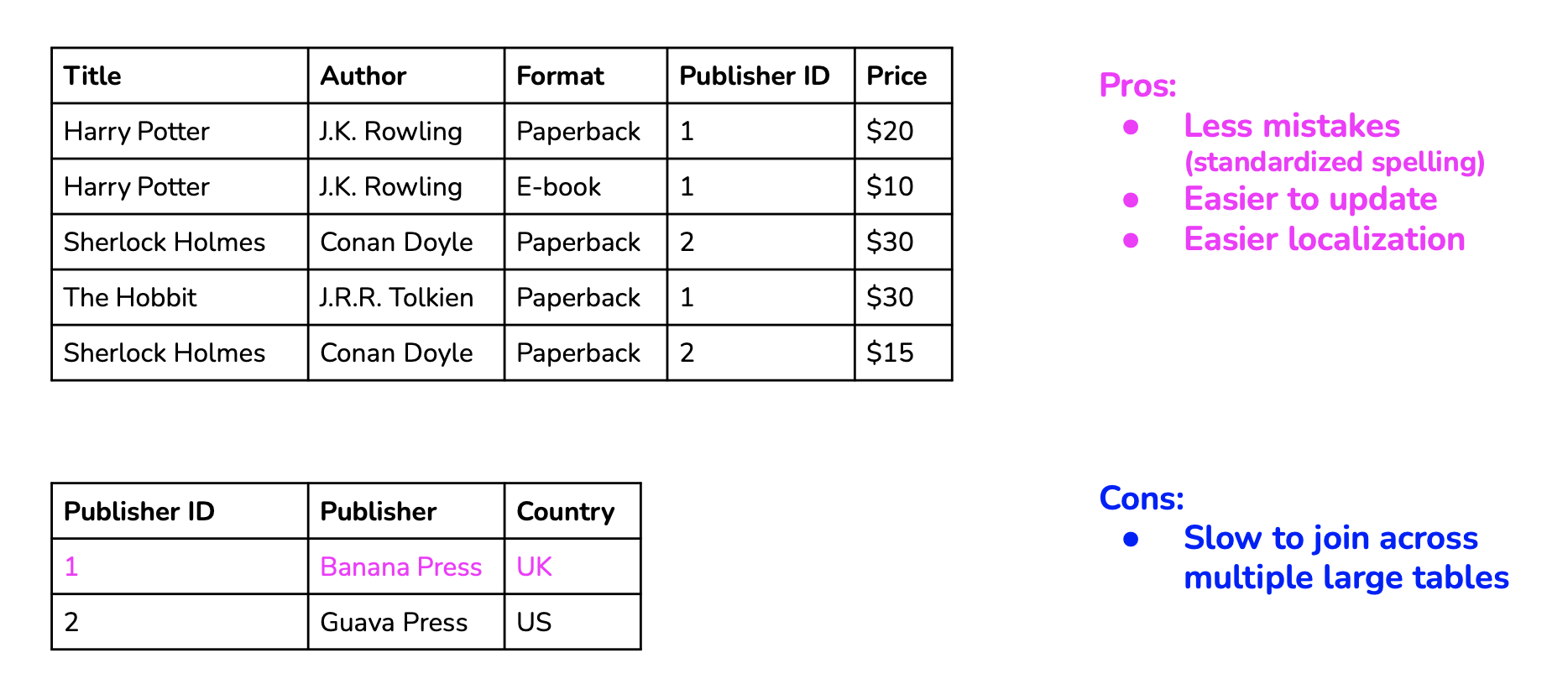
Normalization is using associated values to index, the mapping being stored in a table:
JSON is an example of NoSQL format.
Extract is extracting the data you want from data sources. Your data will likely come from multiple sources in different formats. Some of them will be corrupted or malformatted. In the extracting phase, you need to validate your data and reject the data that doesn’t meet your requirements. For rejected data, you might have to notify the sources. Since this is the first step of the process, doing it correctly can save you a lot of time downstream,
Transform is the meaty part of the process, where most of the data processing is done. You might want to join data from multiple sources and clean it. You might want to standardize the value ranges (e.g. one data source might use “Male” and “Female” for genders, but another uses “M” and “F” or “1” and “2”). You can apply operations such as transposing, deduplicating, sorting, aggregating, deriving new features, more data validating, etc,
Load is deciding how and how often to load your transformed data into the target destination, which can be a file, a database, or a data warehouse.
See: