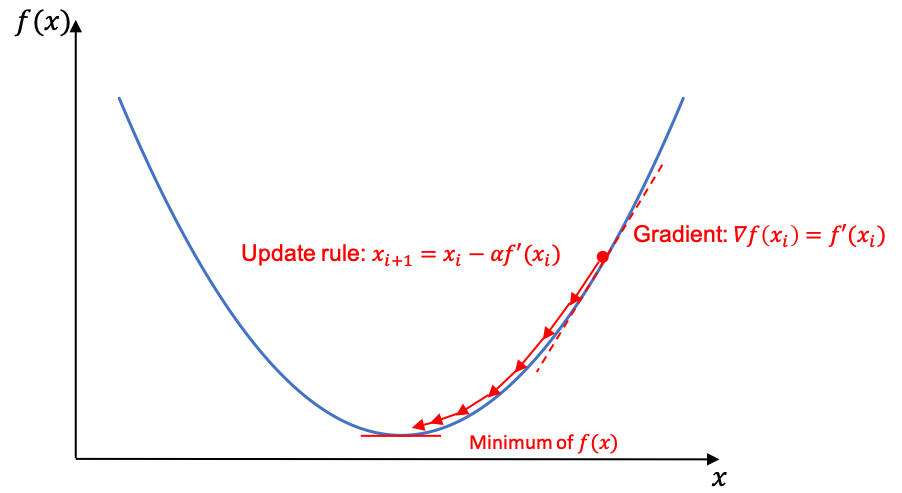
Gradient descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function. To find the minimum of a function \(f\) it starts with an initial guess \(x_0\) and then will update its guess using the gradient descent rule:
\[x_{i+1} = x_{i} - \alpha \frac{df(x_i)}{dx_i}\]Where:
Using the formulation:
\[f(a+h) = f(a)+\frac{f'(a)}{1!}h+\frac{f^{(2)}(a)}{2!}h^2 + ... + \frac{f^{(k)}(a)}{k!}h^k + o(h^k)\]up to the first derivative we get:
\[\begin{eqnarray} f(a+h) &&= f(a)+\frac{f'(a)}{1!}h + o(h) \\ &&= f(a) + h \cdot f'(a) + o(h) \end{eqnarray}\]In this setup, we look for the step \(h\) that will decrease the value of the function:
Hence we could choose \(h=-sign(f'(a))\).
But the gradient descent algorithm choose another option: \(h=-\alpha f'(a)\). Using this formulation of \(h\), \(h \cdot f'(a)\) is still negative and \(f(a+h)\) smaller than \(f(a)\).
Why the value of \(h\) is relative to the magnitude of \(f'(a)\) and not just its sign? The answer is that for smooth functions, the gradient of a function is expected to decrease as we moove closer to the minimum hence the steps are expected to be smallers.
See Wikipedia page for Gradient Descent.
Newton’s method is an iterative optimization algorithm for finding the roots of a differentiable function \(f\), which are solution of \(f(x)=0\).
If \(f\) is twice differentiable, Newton’s method can be applied to the derivative of \(f\), \(f'\) in order to find the minimum (or maximum or saddle point) of \(f\) (as \(f(x)\) is \(\max\) or \(\min\) or saddle point if \(f'(x)=0\)).
To find the zero of a function \(f\) Newton’s method starts with an initial guess \(x_0\) and the update rule is:
\[x_{i+1} = x_{i} - \frac{f(x_i)}{f'(x_i)}\]Let’s now focus on the optimization objective (minimization). We will give more details in this following part.
To find the minimum of a function \(f\) Newton’s method starts with an initial guess \(x^0\) and then will update its guess using a second order rule:
\[x_{i+1} = x_{i} - \alpha \frac{f'(x_i)}{f^{(2)}(x_i)}\]Where:
The update rule is similar to the one in gradient descent but it is scaled by the inverse of the second derivative of \(f\).
In higher dimension we obtain:
\[x_{i+1} = x_{i} - \alpha \left(\triangledown^{2}f(x_i)\right)^{-1} \triangledown f(x_i)\]Where:
Newton’s method uses the second order approximation of the Taylor expansion of the function \(f\).
\[\begin{eqnarray} f(a+h) &&= f(a) + \frac{f'(a)}{1!}h + \frac{f^{(2)}(a)}{2!}h^2 + o(h^2) \\ &&= f(a) + h \cdot f'(a) + h^2 \cdot \frac{1}{2}f^{(2)}(a) + o(h^2) \end{eqnarray}\]Using \(x_i\) we get:
\[f(x_i+h) = f(x_i) + h \cdot f'(x_i) + h^2 \cdot \frac{1}{2}f^{(2)}(x_i) + o(h^2)\]The current guess \(x_i\) for the minimum (or maximum) of the function \(f\) gives an associated minimum value \(f(x_i)\) and its derivative is \(f'(x_i)\). If \(f'(x_i)=0\) we are done. Otherwise we search a new \(x_{i+1}\) such that \(f'(x_{i+1})=0\). Equivalently we search \(h\) such that \(f'(x_i+h)=0\) (\(x_{i+1} = x_i + h\)).
Note that the sense of the optimization is dependent of the second derivative of \(f\). If \(f^{(2)}(x) \gt 0\) then we are converging to a minimum, otherwise to a maximum.
For small step \(h\) we can apply the Taylor’s theorem to the neighbourhood of \(x_i\) until order two (or order one for gradient descent). We then compute the derivative and set it to 0:
Hence, the update rule for \(x_{i+1}\) is:
\[x_{i+1} = x_{i} - \frac{f'(x_i)}{f^{(2)}(x_i)}\]We can add an hyperparameter \(\alpha\) to scale the step.
See Wikipedia page for Newton’s method.
When finding a flat point of a function \(f\), ie a point \(x\) for which the derivative is null, \(f'(x)=0\) we do not know if the point is a minimum or a maximum.
The second derivative however gives us the information:
\(f^{(2)}(x) \gt 0\) means that the derivative of \(f\) will get bigger in the neighbourhood of \(f\), hence becoming positive as \(f'(x)=0\) and hence \(f(x)\) will get bigger.
\(f^{(2)}(x) \lt 0\) means that the derivative of \(f\) will get smaller in the neighbourhood of \(f\), hence becoming negative as \(f'(x)=0\) and hence \(f(x)\) will get smaller.