
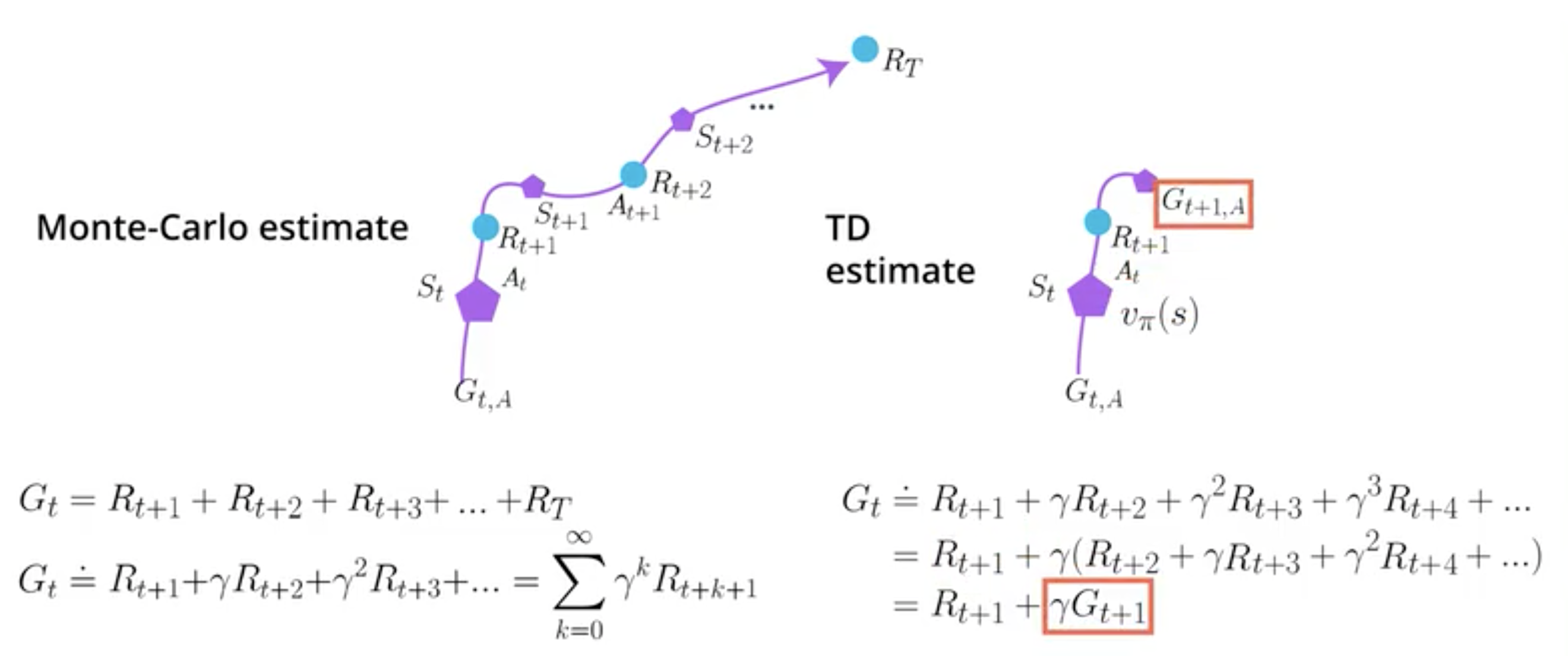
MC method takes the value \(G_t\) as alternative estimate. \(G_t\) is the return computed using the future states of the episode. TD methods makes its alternative estimate based on the observed return and the next state/action estimate. Hence TD does not require the whole episode to make its guess of alternative estimate.
Monte-Carlo method returns an unbiaised estimator but with high variance, as for each episode it cumulates different random values (the rewards are random as well as the next states).
Temporal difference method is biaised as the return of the next state is estimated (\(G_{t+1}\)) but it has low variance (as it does not cumulate different random values).
This picture highlights the high number of random values in MC method and the estimate \(G_{t+1}\) in TD method:
See: