
Deep Reinforcement Learning is the application of (deep) neural network for reinforcement learning.
The classical approaches deal with finite Markov Decision Process with a finite number of states and actions. However in real applications, the number of states and actions can be infinite if the states and actions are continuous values.
They use tables to store state value function and action value function (the \(Q\)-table for example). The term function is used in these method to refer to state and action value functions but these functions must be seen as mapping or tables. In continuous environment using mapping or tables is no longer possible.
Deep Reinforcement methods can deal continuous (inifinite) states space and (for some) continuous action space.
\(v_\pi\) and \(q_\pi\) are now true unknown continuous functions that we need to approximate. We thus seek \(\hat{v}\) and \(\hat{q}\) that will approximate \(v_\pi\) and \(q_\pi\).
Typically \(\hat{v}\) and \(\hat{q}\) will be parametrized by weights \(w\) and will be neural networks:
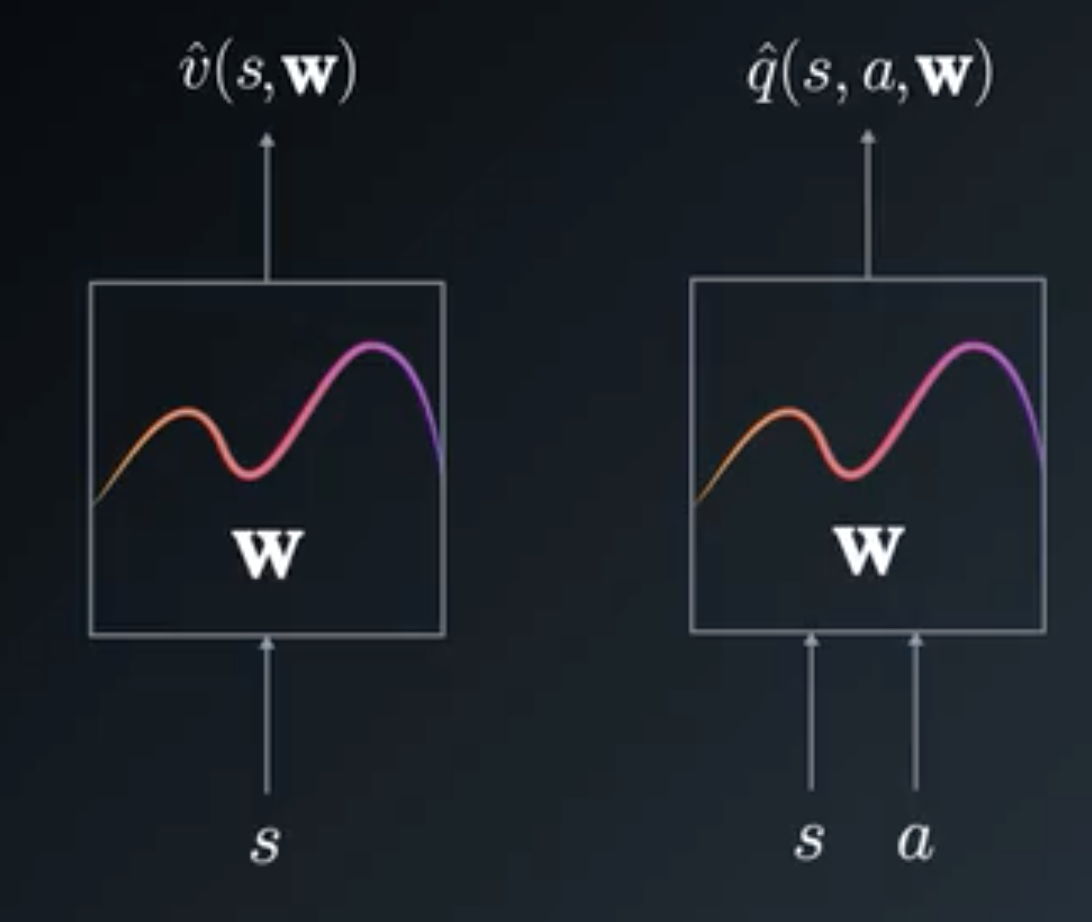
Also in Deep Reinforcement Learning the steps of estimating the value functions (state or action or both) and then updating the policy using the \(\varepsilon\)-greedy method is done at the same time. The value functions are updated and the policy is also updated at the same time.
A car moves in a continuous environment with continuous actions:
Let’s introduce some notations: