In [11]:
df.plot(kind="line")
Out[11]:
<AxesSubplot:>

import numpy as np
import pandas as pd
path = "/Users/jean-baptistegheeraert/Documents/Etudes_Travail/Entretiens_Revisions/Coding/Data Manipulation/Pandas/"
mydict = [{'a': 1, 'c': 3, 'b': 2, 'd': 4},
{'a': 10, 'c': 300, 'b': 200, 'd': 400},
{'a': 1000, 'c': 3000, 'b': 2000, 'd': 4000 }]
df = pd.DataFrame(mydict, index=["Row1", "Row2", "Row3"])
df_na = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, np.nan],
[np.nan, 3, np.nan, 4]],
columns=list("ABCD"))
df_groupby = pd.DataFrame({'Animal': ['Falcon', 'Falcon',
'Parrot', 'Parrot',
'Falcon'],
'Type': ['Captive', 'Wild',
'Captive', 'Wild',
'Wild'],
'Max Speed': [380., 370., 24., 26., 400],
'Height': [110, 100, 30, 45, 130]})
df_import = pd.read_csv(path + "assets/data/rotten_tomatoes_movies.csv", sep=",", decimal=".", index_col=0)
#df_import = pd.read_excel('file.xlsx', index_col=0)
#df_import = pd.read_csv(path + "data/rotten_tomatoes_movies.csv", sep=";", decimal=",", chunk_size=1, index_col=0) # read chunk_size line by chunk_size
data_df = list()
with open("./assets/data/rotten_tomatoes_movies.csv") as f:
for line in f:
data_line = line.split(",") # "," is the sep
# make modification on data_line to reduce size
data_df += [data_line]
df_import = pd.DataFrame(data_df).dropna(axis=1)
df_import = df_import.rename(columns=df_import.iloc[0]).drop(df_import.index[0], axis=0)
df_import.to_csv("./assets/data/out.csv", sep=";", decimal=",", index=True)
df_import.to_excel("./assets/data/out.xlsx", sheet_name="Sheet1", index=True)
d = dict()
df_empty = pd.DataFrame(data=d, index=[])
l = list()
df_empty = pd.DataFrame(data=l, columns=[], index=[])
print('1 ---------')
print(df.describe())
print("\n2 ---------")
print(df.head())
print("\n3 ---------")
print(df.tail())
1 ---------
a c b d
count 3.000000 3.000000 3.000000 3.000000
mean 337.000000 1101.000000 734.000000 1468.000000
std 574.192476 1651.273145 1100.848763 2201.697527
min 1.000000 3.000000 2.000000 4.000000
25% 5.500000 151.500000 101.000000 202.000000
50% 10.000000 300.000000 200.000000 400.000000
75% 505.000000 1650.000000 1100.000000 2200.000000
max 1000.000000 3000.000000 2000.000000 4000.000000
2 ---------
a c b d
Row1 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
3 ---------
a c b d
Row1 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
print('1 ---------')
print(df.shape)
print("\n2 ---------")
print(df["a"].value_counts())
print("\n3 ---------")
print(df_na.isna().sum())
print("\n4 ---------")
print(df_na.isnull().sum())
print("\n5 ---------")
print(df.dtypes)
print("\n6 ---------")
print(df.index.dtype)
1 --------- (3, 4) 2 --------- 1 1 10 1 1000 1 Name: a, dtype: int64 3 --------- A 3 B 1 C 4 D 1 dtype: int64 4 --------- A 3 B 1 C 4 D 1 dtype: int64 5 --------- a int64 c int64 b int64 d int64 dtype: object 6 --------- object
print('1 ---------')
print(df.sum())
print("\n2 ---------")
print(df.mean())
print("\n3 ---------")
print(df.median())
print("\n4 ---------")
print(df.std())
print("\n5 ---------")
print(df.quantile(0.1))
print("\n6 ---------")
print(df.corr())
1 ---------
a 1011
c 3303
b 2202
d 4404
dtype: int64
2 ---------
a 337.0
c 1101.0
b 734.0
d 1468.0
dtype: float64
3 ---------
a 10.0
c 300.0
b 200.0
d 400.0
dtype: float64
4 ---------
a 574.192476
c 1651.273145
b 1100.848763
d 2201.697527
dtype: float64
5 ---------
a 2.8
c 62.4
b 41.6
d 83.2
Name: 0.1, dtype: float64
6 ---------
a c b d
a 1.000000 0.996622 0.996622 0.996622
c 0.996622 1.000000 1.000000 1.000000
b 0.996622 1.000000 1.000000 1.000000
d 0.996622 1.000000 1.000000 1.000000
df.plot(kind="line")
<AxesSubplot:>
df.boxplot()
<AxesSubplot:>

print('1 ---------')
print(df.dtypes)
print('\n2 ---------')
print(df.astype('int16').dtypes)
print('\n3 ---------')
print(df.select_dtypes(include=np.number)) # select columns based on dtype
1 ---------
a int64
c int64
b int64
d int64
dtype: object
2 ---------
a int16
c int16
b int16
d int16
dtype: object
3 ---------
a c b d
Row1 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
df.T
| Row1 | Row2 | Row3 | |
|---|---|---|---|
| a | 1 | 10 | 1000 |
| c | 3 | 300 | 3000 |
| b | 2 | 200 | 2000 |
| d | 4 | 400 | 4000 |
# iloc -> access by index
print('1 ---------')
print(df.iloc[0,0])
print('\n2 ---------')
print(df.iloc[0])
print('\n3 ---------')
print(df.iloc[0:3, 0:4])
print('\n4 ---------')
print(df.iloc[[0, 2], [1, 2]])
# print(df.iloc[lambda x: x.index % 2 == 0, :]) # for numeric index
# print(df.iloc[:, lambda x: x.columns % 2 == 0]) # for numeric colum names
# loc -> access by names
print('\n5 ---------')
print(df.loc["Row1"])
print('\n6 ---------')
print(df.loc["Row1", "a"])
print('\n7 ---------')
print(df.loc["Row1":"Row3", "a":"b"]) # takes all rows or columns between the ones specified
print('\n8 ---------')
print(df.loc[["Row1", "Row3"], ["a", "d"]])
1 ---------
1
2 ---------
a 1
c 3
b 2
d 4
Name: Row1, dtype: int64
3 ---------
a c b d
Row1 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
4 ---------
c b
Row1 3 2
Row3 3000 2000
5 ---------
a 1
c 3
b 2
d 4
Name: Row1, dtype: int64
6 ---------
1
7 ---------
a c b
Row1 1 3 2
Row2 10 300 200
Row3 1000 3000 2000
8 ---------
a d
Row1 1 4
Row3 1000 4000
df["e"] = df["a"] + df["d"]
# df["e"] = df.apply(lambda x: x["a"]+x["d"], axis=1) # same output
print(df)
df.drop("e", axis=1, inplace=True)
a c b d e Row1 1 3 2 4 5 Row2 10 300 200 400 410 Row3 1000 3000 2000 4000 5000
pd.concat([df, pd.DataFrame(data={"a":10000, "c": 30000, "b":20000, "d": 40000}, index=["Row4"])])
| a | c | b | d | |
|---|---|---|---|---|
| Row1 | 1 | 3 | 2 | 4 |
| Row2 | 10 | 300 | 200 | 400 |
| Row3 | 1000 | 3000 | 2000 | 4000 |
| Row4 | 10000 | 30000 | 20000 | 40000 |
print('1 ---------')
# reindex with natural indexing (1 .. n) and drop or transform index in col
print(df.reset_index(drop=False, inplace=False))
print('\n2 ---------')
print(df.reindex(index=["Row3", "Row1", "Row2"])) # reindex expects values already in index otherwise -> nan
print('\n3 ---------')
print(df.set_index("a")) # set column as index
print('\n4 ---------')
df.index = list("jbg")
print(df)
df.index = ["Row1", "Row2", "Row3"]
print('\n5 ---------')
print(df.rename(columns={"a":"11", "b": "22", "c":"33", "d":"44"})) # rename columns using the map d_map (a dict)
print('\n6 ---------')
print(df.rename(index={"Row1": "RenamedRow"})) # rename index using the map d_map (a dict)
print('\n7 ---------')
print(df.loc[:, "a"].rename("test")) # rename works with Series too
print('\n8 ---------')
df.columns = ["e", "f", "g", "h"]
print(df)
df.columns = ["a", "c", "b", "d"]
1 ---------
index a c b d
0 Row1 1 3 2 4
1 Row2 10 300 200 400
2 Row3 1000 3000 2000 4000
2 ---------
a c b d
Row3 1000 3000 2000 4000
Row1 1 3 2 4
Row2 10 300 200 400
3 ---------
c b d
a
1 3 2 4
10 300 200 400
1000 3000 2000 4000
4 ---------
a c b d
j 1 3 2 4
b 10 300 200 400
g 1000 3000 2000 4000
5 ---------
11 33 22 44
Row1 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
6 ---------
a c b d
RenamedRow 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
7 ---------
Row1 1
Row2 10
Row3 1000
Name: test, dtype: int64
8 ---------
e f g h
Row1 1 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
df.sort_values(["a", "b"], ascending=[False, True])
| a | c | b | d | |
|---|---|---|---|---|
| Row3 | 1000 | 3000 | 2000 | 4000 |
| Row2 | 10 | 300 | 200 | 400 |
| Row1 | 1 | 3 | 2 | 4 |
df.sort_index(level=[0], ascending=False)
| a | c | b | d | |
|---|---|---|---|---|
| Row3 | 1000 | 3000 | 2000 | 4000 |
| Row2 | 10 | 300 | 200 | 400 |
| Row1 | 1 | 3 | 2 | 4 |
print('1 ---------')
print(df_na.dropna(axis=1, how='any'))
print('\n2 ---------')
print(df_na.dropna(axis=1, how='all')) # drops column C
print('\n3 ---------')
print(df_na.dropna(axis=0, how='all')) # drops row 2
1 ---------
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3]
2 ---------
A B D
0 NaN 2.0 0.0
1 3.0 4.0 1.0
2 NaN NaN NaN
3 NaN 3.0 4.0
3 ---------
A B C D
0 NaN 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
3 NaN 3.0 NaN 4.0
print('1 ---------')
print(df_na.fillna(0)) # replace with 0
print('\n2 ---------')
print(df_na.fillna(method="ffill", axis=0)) # replace with precedent valid value (axis=0 -> ffill with previous row)
print('\n3 ---------')
print(df_na.fillna(df_na.mean(), axis=0, inplace=False)) # replace with column mean
1 ---------
A B C D
0 0.0 2.0 0.0 0.0
1 3.0 4.0 0.0 1.0
2 0.0 0.0 0.0 0.0
3 0.0 3.0 0.0 4.0
2 ---------
A B C D
0 NaN 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 3.0 4.0 NaN 1.0
3 3.0 3.0 NaN 4.0
3 ---------
A B C D
0 3.0 2.0 NaN 0.000000
1 3.0 4.0 NaN 1.000000
2 3.0 3.0 NaN 1.666667
3 3.0 3.0 NaN 4.000000
df[df.a % 100 == 0]
| a | c | b | d | |
|---|---|---|---|---|
| Row3 | 1000 | 3000 | 2000 | 4000 |
df[~ (df.b % 1000 == 0)]
| a | c | b | d | |
|---|---|---|---|---|
| Row1 | 1 | 3 | 2 | 4 |
| Row2 | 10 | 300 | 200 | 400 |
df.filter(items=["a", "b"], axis=1)
| a | b | |
|---|---|---|
| Row1 | 1 | 2 |
| Row2 | 10 | 200 |
| Row3 | 1000 | 2000 |
df.filter(like="ow3", axis=0)
| a | c | b | d | |
|---|---|---|---|---|
| Row3 | 1000 | 3000 | 2000 | 4000 |
df.filter(regex='[2-3]$', axis=0)
| a | c | b | d | |
|---|---|---|---|---|
| Row2 | 10 | 300 | 200 | 400 |
| Row3 | 1000 | 3000 | 2000 | 4000 |
# All equivalent
print('1 ---------')
print(df_na[df_na.A.isna()])
print('\n2 ---------')
print(df_na[df_na.A.isna()])
print('\n3 ---------')
print(df_na[pd.isnull(df_na.A)])
1 ---------
A B C D
0 NaN 2.0 NaN 0.0
2 NaN NaN NaN NaN
3 NaN 3.0 NaN 4.0
2 ---------
A B C D
0 NaN 2.0 NaN 0.0
2 NaN NaN NaN NaN
3 NaN 3.0 NaN 4.0
3 ---------
A B C D
0 NaN 2.0 NaN 0.0
2 NaN NaN NaN NaN
3 NaN 3.0 NaN 4.0
print('1 ---------')
print(df_na[pd.notnull(df_na.A)])
print('\n2 ---------')
print(df_na[~ df_na.A.isna()])
1 ---------
A B C D
1 3.0 4.0 NaN 1.0
2 ---------
A B C D
1 3.0 4.0 NaN 1.0
df_na[(df_na.B >= 3) & (pd.notnull(df_na.D))]
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 3.0 | 4.0 | NaN | 1.0 |
| 3 | NaN | 3.0 | NaN | 4.0 |
print('1 ---------')
print(df.replace(to_replace={1: 121}))
print('\n2 ---------')
print(df.replace(to_replace=1, value=121))
1 ---------
a c b d
Row1 121 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
2 ---------
a c b d
Row1 121 3 2 4
Row2 10 300 200 400
Row3 1000 3000 2000 4000
df_text = pd.DataFrame({"text": ["this is a regular sentence", "https://docs.python.org/3/tutorial/index.html", np.nan],
"nb": [1, 2, 3]})
df_text.text.str.split(expand=True)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | this | is | a | regular | sentence |
| 1 | https://docs.python.org/3/tutorial/index.html | None | None | None | None |
| 2 | NaN | NaN | NaN | NaN | NaN |
print('1 ---------')
print(df_text.text.str.extract(pat="(/[0-9]/)"))
print('\n2 ---------')
print(df_text.text.str.contains(pat="/[0-9]/"))
print('\n2 ---------')
print(df_text.text.str.startswith(pat="this"))
1 ---------
0
0 NaN
1 /3/
2 NaN
2 ---------
0 False
1 True
2 NaN
Name: text, dtype: object
2 ---------
0 True
1 False
2 NaN
Name: text, dtype: object
# apply applies a function along axis 0 or index: apply to each column and 1 or columns apply to each row
print('1 ---------')
print(df.apply(lambda x: sum(x), axis=0))
print('\n2 ---------')
print(df.apply(lambda x: sum(x), axis=1))
# expand will expands list results as different rows or columns
print('\n3 ---------')
print(df.apply(lambda x: [x.mean(), x.std()], axis=0, result_type='expand'))
1 ---------
a 1011
c 3303
b 2202
d 4404
dtype: int64
2 ---------
Row1 10
Row2 910
Row3 10000
dtype: int64
3 ---------
a c b d
0 337.000000 1101.000000 734.000000 1468.000000
1 574.192476 1651.273145 1100.848763 2201.697527
df.agg(['sum', 'min'], axis=0)
| a | c | b | d | |
|---|---|---|---|---|
| sum | 1011 | 3303 | 2202 | 4404 |
| min | 1 | 3 | 2 | 4 |
df.agg({'a' : ['sum', 'min'], 'b' : ['min', 'max']}, axis=0)
| a | b | |
|---|---|---|
| sum | 1011.0 | NaN |
| min | 1.0 | 2.0 |
| max | NaN | 2000.0 |
# map applies a function to each element of a Series (does not work on DataFrame)
df.loc[:, "a"].map(lambda x: x**2)
Row1 1 Row2 100 Row3 1000000 Name: a, dtype: int64
# applymap is the equivalent of map for DataFrame: it applies a function to each element
df.applymap(lambda x: x**2)
| a | c | b | d | |
|---|---|---|---|---|
| Row1 | 1 | 9 | 4 | 16 |
| Row2 | 100 | 90000 | 40000 | 160000 |
| Row3 | 1000000 | 9000000 | 4000000 | 16000000 |
df.transform([np.sqrt, np.log], axis=0)
| a | c | b | d | |||||
|---|---|---|---|---|---|---|---|---|
| sqrt | log | sqrt | log | sqrt | log | sqrt | log | |
| Row1 | 1.000000 | 0.000000 | 1.732051 | 1.098612 | 1.414214 | 0.693147 | 2.000000 | 1.386294 |
| Row2 | 3.162278 | 2.302585 | 17.320508 | 5.703782 | 14.142136 | 5.298317 | 20.000000 | 5.991465 |
| Row3 | 31.622777 | 6.907755 | 54.772256 | 8.006368 | 44.721360 | 7.600902 | 63.245553 | 8.294050 |
df_groupby.groupby(by=["Animal"], axis=0).get_group("Falcon") # can groupby columns
| Animal | Type | Max Speed | Height | |
|---|---|---|---|---|
| 0 | Falcon | Captive | 380.0 | 110 |
| 1 | Falcon | Wild | 370.0 | 100 |
| 4 | Falcon | Wild | 400.0 | 130 |
print('1 ---------')
print(df_groupby.groupby(["Animal"])["Height"].mean())
print('\n2 ---------')
print(df_groupby.groupby(["Type"]).std())
print('\n3 ---------')
print(df_groupby.groupby(["Animal", "Type"]).sum())
print('\n4 ---------')
df_groupby.groupby(by=["Animal"], axis=0).size()
1 ---------
Animal
Falcon 113.333333
Parrot 37.500000
Name: Height, dtype: float64
2 ---------
Max Speed Height
Type
Captive 251.730014 56.568542
Wild 207.810811 43.108391
3 ---------
Max Speed Height
Animal Type
Falcon Captive 380.0 110
Wild 770.0 230
Parrot Captive 24.0 30
Wild 26.0 45
4 ---------
Animal Falcon 3 Parrot 2 dtype: int64
# return first element of the group
print(df_groupby.groupby(["Animal"]).apply(lambda x: x.iloc[0]).reset_index(drop=True))
# From Kaggle course -> return best in group (here best by country and province)
# reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()])
Animal Type Max Speed Height 0 Falcon Captive 380.0 110 1 Parrot Captive 24.0 30
df_groupby.groupby(["Animal"]).agg(min)
| Type | Max Speed | Height | |
|---|---|---|---|
| Animal | |||
| Falcon | Captive | 370.0 | 100 |
| Parrot | Captive | 24.0 | 30 |
df_groupby.groupby(["Animal"]).agg({"Max Speed": [min, max, "median", "std"], "Height": "std"})
# g.columns = [" - ".join(x) for x in g.columns]
| Max Speed | Height | ||||
|---|---|---|---|---|---|
| min | max | median | std | std | |
| Animal | |||||
| Falcon | 370.0 | 400.0 | 380.0 | 15.275252 | 15.275252 |
| Parrot | 24.0 | 26.0 | 25.0 | 1.414214 | 10.606602 |
# transform keeps the same index but replace values
df_groupby.drop("Type", axis=1).groupby(["Animal"]).transform(sum)
| Max Speed | Height | |
|---|---|---|
| 0 | 1150.0 | 340 |
| 1 | 1150.0 | 340 |
| 2 | 50.0 | 75 |
| 3 | 50.0 | 75 |
| 4 | 1150.0 | 340 |
df_groupby.groupby(by=["Animal"]).plot(kind="box", legend=True)
Animal Falcon AxesSubplot(0.125,0.125;0.775x0.755) Parrot AxesSubplot(0.125,0.125;0.775x0.755) dtype: object


df1, df2, df3 = df, df*2, df*10
# default is axis=0, ignore_index=True, join="outer"
pd.concat([df1, df2, df3], axis=0, ignore_index=True, join="outer") # add more rows ; join="outer", "inner"
| a | c | b | d | |
|---|---|---|---|---|
| 0 | 1 | 3 | 2 | 4 |
| 1 | 10 | 300 | 200 | 400 |
| 2 | 1000 | 3000 | 2000 | 4000 |
| 3 | 2 | 6 | 4 | 8 |
| 4 | 20 | 600 | 400 | 800 |
| 5 | 2000 | 6000 | 4000 | 8000 |
| 6 | 10 | 30 | 20 | 40 |
| 7 | 100 | 3000 | 2000 | 4000 |
| 8 | 10000 | 30000 | 20000 | 40000 |
pd.concat([df1, df2, df3], axis=1, ignore_index=True, join="outer") # add more columns ; join="outer", "inner"
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Row1 | 1 | 3 | 2 | 4 | 2 | 6 | 4 | 8 | 10 | 30 | 20 | 40 |
| Row2 | 10 | 300 | 200 | 400 | 20 | 600 | 400 | 800 | 100 | 3000 | 2000 | 4000 |
| Row3 | 1000 | 3000 | 2000 | 4000 | 2000 | 6000 | 4000 | 8000 | 10000 | 30000 | 20000 | 40000 |
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'], 'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'], 'value': [5, 6, 7, 8]})
df1
| lkey | value | |
|---|---|---|
| 0 | foo | 1 |
| 1 | bar | 2 |
| 2 | baz | 3 |
| 3 | foo | 5 |
df2
| rkey | value | |
|---|---|---|
| 0 | foo | 5 |
| 1 | bar | 6 |
| 2 | baz | 7 |
| 3 | foo | 8 |
# default how="inner"
pd.merge(df1, df2, left_on=["lkey"], right_on=["rkey"], # if common columns can use 'on'
how="inner", # how="inner",'left', 'right', 'outer'
left_index=False, right_index=False, suffixes=("_x", "_y"), sort=False)
# df1.merge(df2) # equivalent
| lkey | value_x | rkey | value_y | |
|---|---|---|---|---|
| 0 | foo | 1 | foo | 5 |
| 1 | foo | 1 | foo | 8 |
| 2 | foo | 5 | foo | 5 |
| 3 | foo | 5 | foo | 8 |
| 4 | bar | 2 | bar | 6 |
| 5 | baz | 3 | baz | 7 |
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2'], 'B': ['B0', 'B1', 'B2']})
left
| key | A | |
|---|---|---|
| 0 | K0 | A0 |
| 1 | K1 | A1 |
| 2 | K2 | A2 |
| 3 | K3 | A3 |
| 4 | K4 | A4 |
| 5 | K5 | A5 |
right
| key | B | |
|---|---|---|
| 0 | K0 | B0 |
| 1 | K1 | B1 |
| 2 | K2 | B2 |
# default how="left"
left.join(right, how="left", # how="inner",'left', 'right', 'outer'
lsuffix="_x", rsuffix="_y", sort=False)
left.set_index('key').join(right.set_index('key')) # default join on index
| A | B | |
|---|---|---|
| key | ||
| K0 | A0 | B0 |
| K1 | A1 | B1 |
| K2 | A2 | B2 |
| K3 | A3 | NaN |
| K4 | A4 | NaN |
| K5 | A5 | NaN |
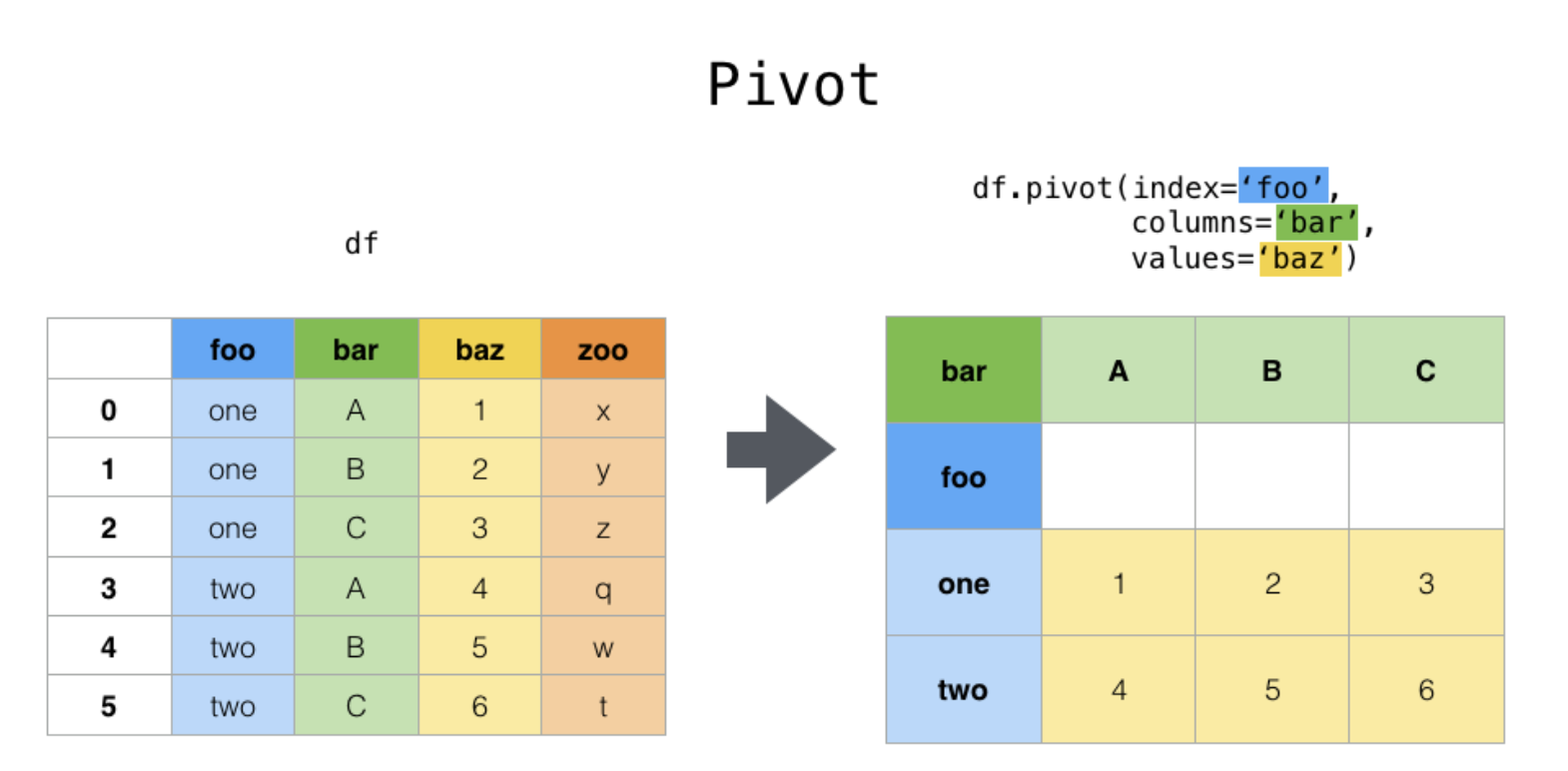
df_pivot = pd.DataFrame(data={"foo": ["one", "one", "one", "two", "two", "two"],
"bar": ["A", "B", "C", "A", "B", "C"],
"baz": [1, 2, 3, 4, 5, 6],
"zoo": ["x", "y", "z", "q", "w", "t"]})
df_pivoted = df_pivot.pivot(index=["foo"], columns=["bar"], values="baz") # can use list of columns for each param
df_pivoted
| bar | A | B | C |
|---|---|---|---|
| foo | |||
| one | 1 | 2 | 3 |
| two | 4 | 5 | 6 |
df_pivot.pivot(index=["foo"], columns=["bar"], values=["baz", "zoo"])
| baz | zoo | |||||
|---|---|---|---|---|---|---|
| bar | A | B | C | A | B | C |
| foo | ||||||
| one | 1 | 2 | 3 | x | y | z |
| two | 4 | 5 | 6 | q | w | t |
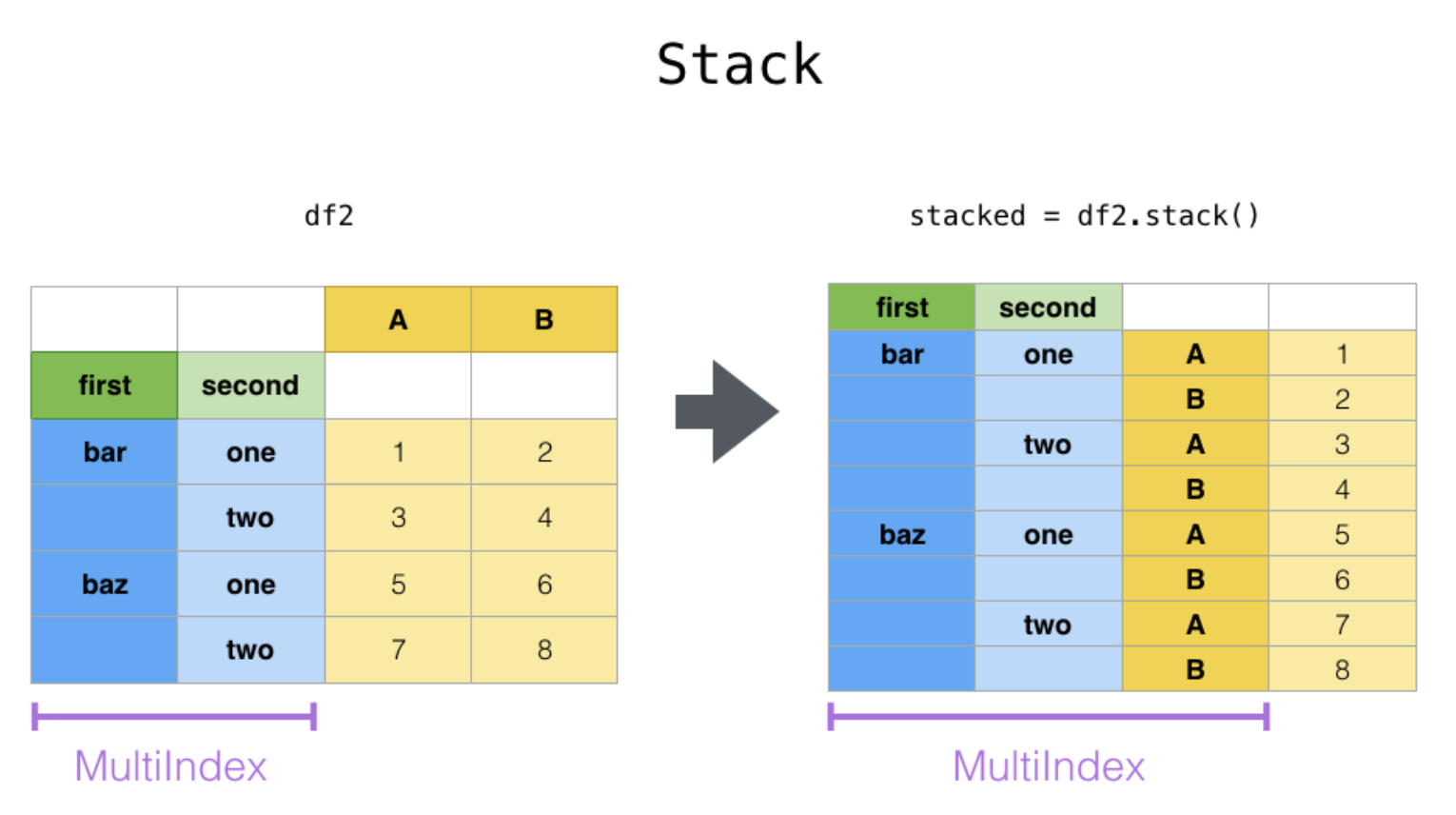
df_stack = pd.DataFrame(data={"dog": ["Rex", "Snoopy", "Sultan", "Polak"],
"cat": ["Simba", "Minette", "Hermione", "Grisette"]},
index=pd.MultiIndex.from_tuples([("Seyssins", "JB"), ("Seyssins", "Isa"),
("Saint-Quentin", "JB"), ("Saint-Quentin", "Isa")],
names=["city", "owner"]))
series_stacked = df_stack.stack(level=-1) # series
series_stacked
city owner
Seyssins JB dog Rex
cat Simba
Isa dog Snoopy
cat Minette
Saint-Quentin JB dog Sultan
cat Hermione
Isa dog Polak
cat Grisette
dtype: object
# stack can be used to revert pivot
df_pivoted.stack().reset_index().rename({0:"baz"}, axis=1)
| foo | bar | baz | |
|---|---|---|---|
| 0 | one | A | 1 |
| 1 | one | B | 2 |
| 2 | one | C | 3 |
| 3 | two | A | 4 |
| 4 | two | B | 5 |
| 5 | two | C | 6 |
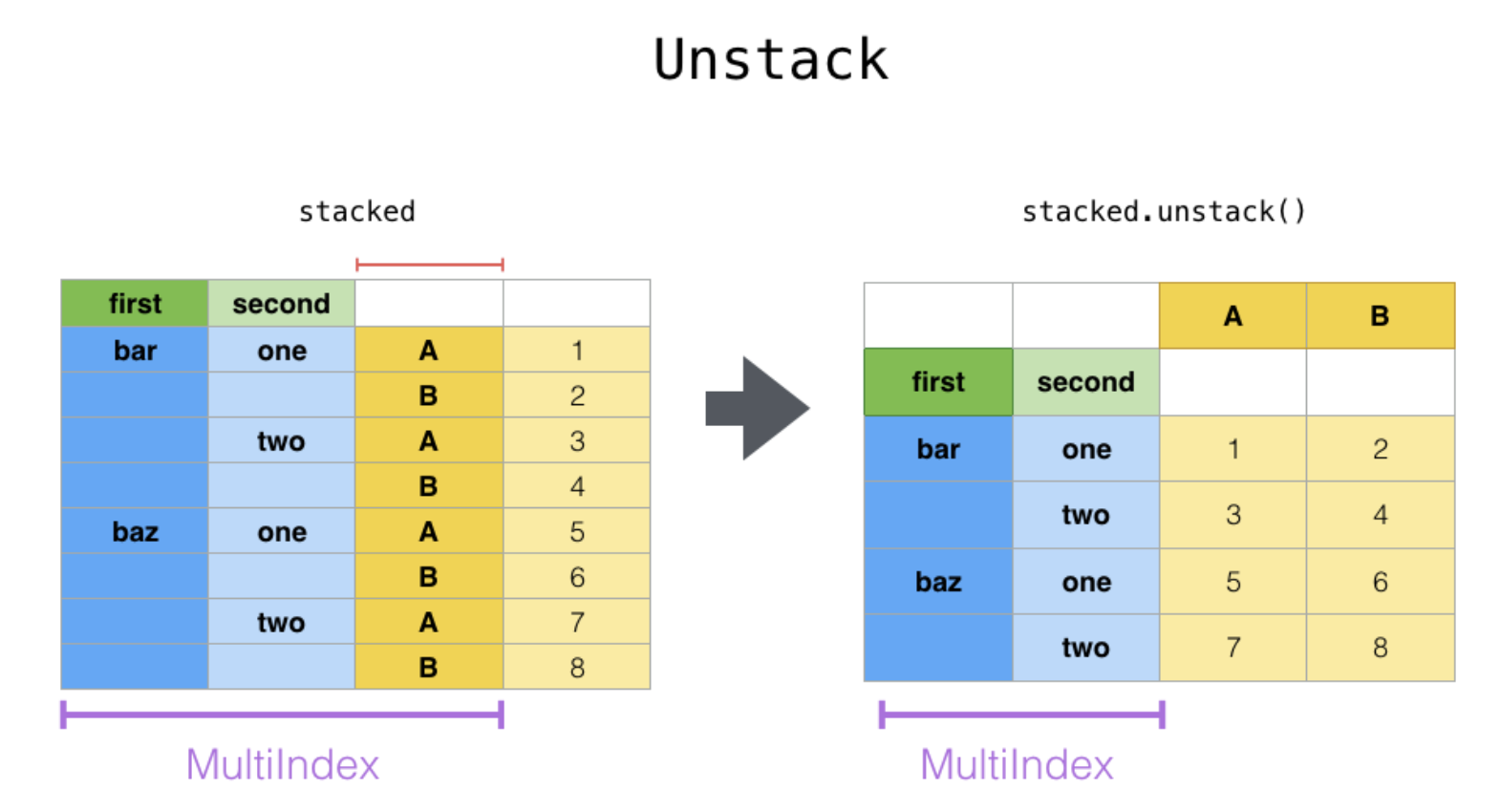
series_stacked
city owner
Seyssins JB dog Rex
cat Simba
Isa dog Snoopy
cat Minette
Saint-Quentin JB dog Sultan
cat Hermione
Isa dog Polak
cat Grisette
dtype: object
print('1 ---------')
print(series_stacked.unstack(level=0))
print('\n2 ---------')
print(series_stacked.unstack(level=1))
print('\n3 ---------')
print(series_stacked.unstack(level=2))
1 ---------
city Saint-Quentin Seyssins
owner
Isa dog Polak Snoopy
cat Grisette Minette
JB dog Sultan Rex
cat Hermione Simba
2 ---------
owner Isa JB
city
Saint-Quentin dog Polak Sultan
cat Grisette Hermione
Seyssins dog Snoopy Rex
cat Minette Simba
3 ---------
dog cat
city owner
Saint-Quentin Isa Polak Grisette
JB Sultan Hermione
Seyssins Isa Snoopy Minette
JB Rex Simba
series_stacked.reset_index().pivot(index=["city", "owner"], columns="level_2", values=0)
| level_2 | cat | dog | |
|---|---|---|---|
| city | owner | ||
| Saint-Quentin | Isa | Grisette | Polak |
| JB | Hermione | Sultan | |
| Seyssins | Isa | Minette | Snoopy |
| JB | Simba | Rex |
# weirdly (or not) unstack can be used to revert pivot -> will create a columns df with 1 row -> cast to series
df_pivoted.unstack().reset_index().rename({0:"baz"}, axis=1)
| bar | foo | baz | |
|---|---|---|---|
| 0 | A | one | 1 |
| 1 | A | two | 4 |
| 2 | B | one | 2 |
| 3 | B | two | 5 |
| 4 | C | one | 3 |
| 5 | C | two | 6 |
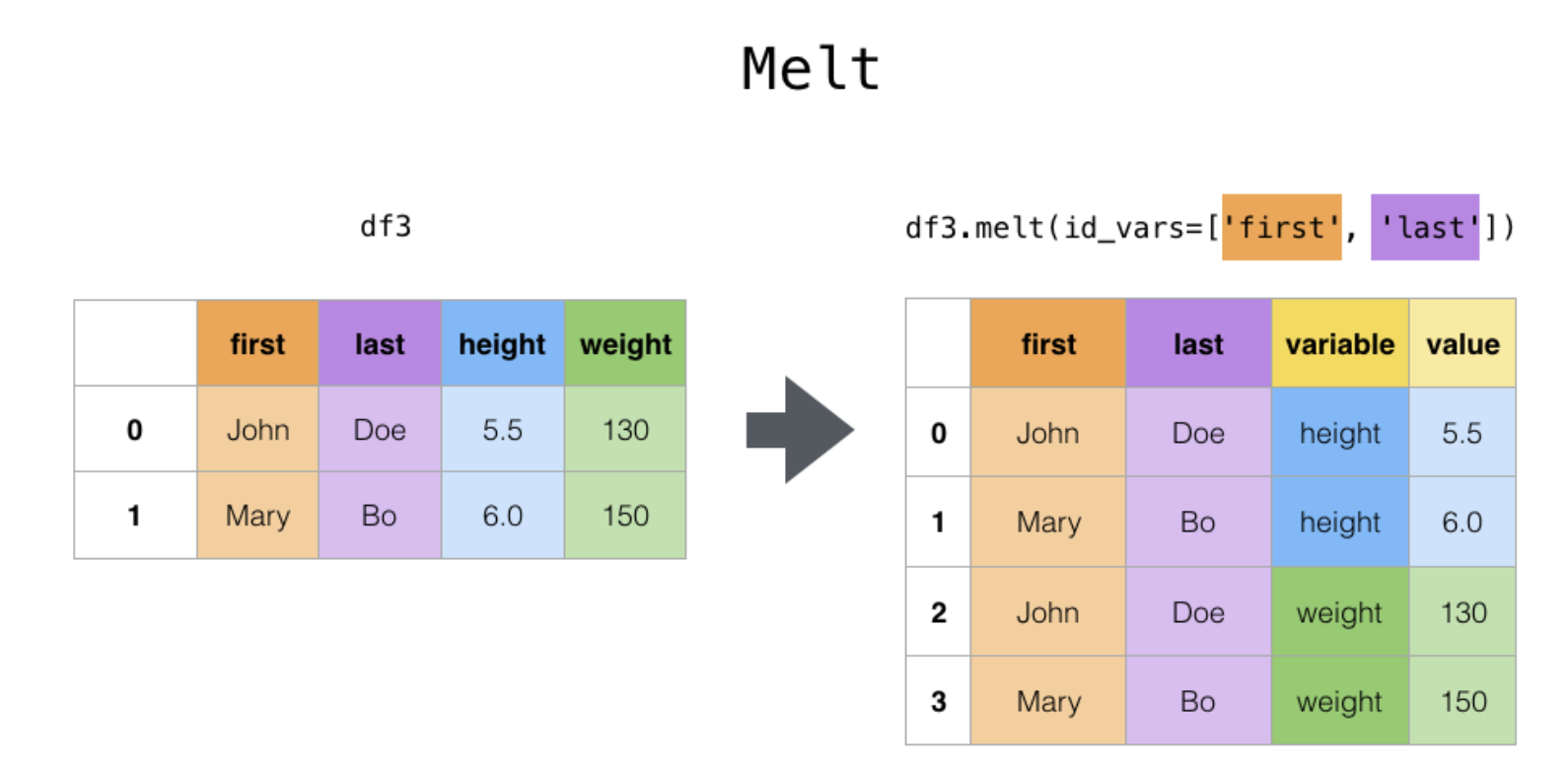
df_pivoted.reset_index()
| bar | foo | A | B | C |
|---|---|---|---|---|
| 0 | one | 1 | 2 | 3 |
| 1 | two | 4 | 5 | 6 |
df_pivoted.reset_index().melt(id_vars=["foo"], value_vars=["A", "B", "C"], value_name="baz") # col_level if multi index
| foo | bar | baz | |
|---|---|---|---|
| 0 | one | A | 1 |
| 1 | two | A | 4 |
| 2 | one | B | 2 |
| 3 | two | B | 5 |
| 4 | one | C | 3 |
| 5 | two | C | 6 |
df_pivot_table = pd.DataFrame(data={"foo": ["one", "one", "one", "one", "two", "two", "two"],
"bar": ["A", "A", "B", "C", "A", "B", "C"],
"baz": [9, 1, 2, 3, 4, 5, 6],
"zoo": ["u", "x", "y", "z", "q", "w", "t"]})
#df_pivot_table.pivot(index=["foo"],columns=["bar"],values="baz") # won't work because of duplicates for ("one", "A")
df_pivot_table.pivot_table(index=["foo"],columns=["bar"],values="baz",aggfunc="mean") # agg duplicate as specified
| bar | A | B | C |
|---|---|---|---|
| foo | |||
| one | 5 | 2 | 3 |
| two | 4 | 5 | 6 |
arrays = [["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
["one", "two", "one", "two", "one", "two", "one", "two"]]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples, names=["first", "second"])
df_index = pd.DataFrame({"A": np.random.randn(8), "B": np.random.randn(8)}, index=index)
print('1 ---------')
print(df_index.index.get_level_values(0))
print('\n2 ---------')
print(df_index.index.get_level_values(1))
1 --------- Index(['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'], dtype='object', name='first') 2 --------- Index(['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two'], dtype='object', name='second')
print('1 ---------')
print(df_index.loc[("bar",),])
print('\n2 ---------')
print(df_index.loc[("bar","one"),])
1 ---------
A B
second
one 0.486983 2.240877
two 0.649708 -0.565609
2 ---------
A 0.486983
B 2.240877
Name: (bar, one), dtype: float64
# to filter one second level use xs
print('1 ---------')
print(df_index.xs("one", level=1, axis=0))
print('\n2 ---------')
print(df_index.xs(("one", "bar"), level=("second", "first"), axis=0))
1 ---------
A B
first
bar 0.486983 2.240877
baz 0.398377 0.466300
foo -0.172727 0.550550
qux 1.431770 0.306032
2 ---------
A B
first second
bar one 0.486983 2.240877
print('1 ---------')
print(df_index.swaplevel(0, 1, axis=0))
print('\n2 ---------')
print(df_index.reorder_levels([1, 0], axis=0))
1 ---------
A B
second first
one bar 0.486983 2.240877
two bar 0.649708 -0.565609
one baz 0.398377 0.466300
two baz -0.143514 -0.250441
one foo -0.172727 0.550550
two foo -0.737634 1.198295
one qux 1.431770 0.306032
two qux 0.673555 0.514267
2 ---------
A B
second first
one bar 0.486983 2.240877
two bar 0.649708 -0.565609
one baz 0.398377 0.466300
two baz -0.143514 -0.250441
one foo -0.172727 0.550550
two foo -0.737634 1.198295
one qux 1.431770 0.306032
two qux 0.673555 0.514267
df_index.sort_index(level=1)
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 0.486983 | 2.240877 |
| baz | one | 0.398377 | 0.466300 |
| foo | one | -0.172727 | 0.550550 |
| qux | one | 1.431770 | 0.306032 |
| bar | two | 0.649708 | -0.565609 |
| baz | two | -0.143514 | -0.250441 |
| foo | two | -0.737634 | 1.198295 |
| qux | two | 0.673555 | 0.514267 |
df_index.droplevel(level=1, axis=0)
| A | B | |
|---|---|---|
| first | ||
| bar | 0.486983 | 2.240877 |
| bar | 0.649708 | -0.565609 |
| baz | 0.398377 | 0.466300 |
| baz | -0.143514 | -0.250441 |
| foo | -0.172727 | 0.550550 |
| foo | -0.737634 | 1.198295 |
| qux | 1.431770 | 0.306032 |
| qux | 0.673555 | 0.514267 |
df_datetime = pd.DataFrame(np.random.randn(10, 1),
columns=["A"],
index=pd.date_range("20210101", periods=10, freq="W"))
s_datetime = pd.date_range("2000-01-01", "2000-01-05").to_series()
print('1 ---------')
print(df_datetime.index.weekday)
print('\n2 ---------')
print(df_datetime.index.day)
print('\n3 ---------')
print(df_datetime.index.month)
print('\n4 ---------')
print(df_datetime.index.year)
print('\n5 ---------')
print(s_datetime.dt.weekday)
1 --------- Int64Index([6, 6, 6, 6, 6, 6, 6, 6, 6, 6], dtype='int64') 2 --------- Int64Index([3, 10, 17, 24, 31, 7, 14, 21, 28, 7], dtype='int64') 3 --------- Int64Index([1, 1, 1, 1, 1, 2, 2, 2, 2, 3], dtype='int64') 4 --------- Int64Index([2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021], dtype='int64') 5 --------- 2000-01-01 5 2000-01-02 6 2000-01-03 0 2000-01-04 1 2000-01-05 2 Freq: D, dtype: int64
df_datetime["2021-1":"2021-2-28"]
| A | |
|---|---|
| 2021-01-03 | -0.589891 |
| 2021-01-10 | 0.318922 |
| 2021-01-17 | -2.492424 |
| 2021-01-24 | 0.430524 |
| 2021-01-31 | -1.257278 |
| 2021-02-07 | 0.493138 |
| 2021-02-14 | -0.329495 |
| 2021-02-21 | 1.265764 |
| 2021-02-28 | 0.628960 |
df_datetime.shift(1, freq="D")
| A | |
|---|---|
| 2021-01-04 | -0.589891 |
| 2021-01-11 | 0.318922 |
| 2021-01-18 | -2.492424 |
| 2021-01-25 | 0.430524 |
| 2021-02-01 | -1.257278 |
| 2021-02-08 | 0.493138 |
| 2021-02-15 | -0.329495 |
| 2021-02-22 | 1.265764 |
| 2021-03-01 | 0.628960 |
| 2021-03-08 | -0.378527 |
df_datetime.resample(rule="M").mean() # mean, sum, ohlc, max, min
| A | |
|---|---|
| 2021-01-31 | -0.718030 |
| 2021-02-28 | 0.514592 |
| 2021-03-31 | -0.378527 |
df_datetime.resample(rule="M").agg([min, max, "sum", "mean"])
| A | ||||
|---|---|---|---|---|
| min | max | sum | mean | |
| 2021-01-31 | -2.492424 | 0.430524 | -3.590148 | -0.718030 |
| 2021-02-28 | -0.329495 | 1.265764 | 2.058367 | 0.514592 |
| 2021-03-31 | -0.378527 | -0.378527 | -0.378527 | -0.378527 |
df_datetime.resample(rule="D").asfreq() # asfreq just upsample data but new rows have value NaN
# possible to interpolate after with .interpolate()
| A | |
|---|---|
| 2021-01-03 | -0.589891 |
| 2021-01-04 | NaN |
| 2021-01-05 | NaN |
| 2021-01-06 | NaN |
| 2021-01-07 | NaN |
| ... | ... |
| 2021-03-03 | NaN |
| 2021-03-04 | NaN |
| 2021-03-05 | NaN |
| 2021-03-06 | NaN |
| 2021-03-07 | -0.378527 |
64 rows × 1 columns
df_datetime.resample(rule="D").ffill() # asfreq, ffill, bfill
| A | |
|---|---|
| 2021-01-03 | -0.589891 |
| 2021-01-04 | -0.589891 |
| 2021-01-05 | -0.589891 |
| 2021-01-06 | -0.589891 |
| 2021-01-07 | -0.589891 |
| ... | ... |
| 2021-03-03 | 0.628960 |
| 2021-03-04 | 0.628960 |
| 2021-03-05 | 0.628960 |
| 2021-03-06 | 0.628960 |
| 2021-03-07 | -0.378527 |
64 rows × 1 columns
df_datetime.rolling(2, min_periods=2, center=False).mean() # sum
| A | |
|---|---|
| 2021-01-03 | NaN |
| 2021-01-10 | -0.135485 |
| 2021-01-17 | -1.086751 |
| 2021-01-24 | -1.030950 |
| 2021-01-31 | -0.413377 |
| 2021-02-07 | -0.382070 |
| 2021-02-14 | 0.081822 |
| 2021-02-21 | 0.468134 |
| 2021-02-28 | 0.947362 |
| 2021-03-07 | 0.125217 |
df_datetime.rolling("30D", min_periods=3, center=False).mean() # sum
| A | |
|---|---|
| 2021-01-03 | NaN |
| 2021-01-10 | NaN |
| 2021-01-17 | -0.921131 |
| 2021-01-24 | -0.583217 |
| 2021-01-31 | -0.718030 |
| 2021-02-07 | -0.501424 |
| 2021-02-14 | -0.631107 |
| 2021-02-21 | 0.120531 |
| 2021-02-28 | 0.160218 |
| 2021-03-07 | 0.335968 |
df_query = pd.DataFrame({'A': range(1, 6), 'B': range(10, 0, -2), 'C C': range(10, 5, -1)})
df_query
| A | B | C C | |
|---|---|---|---|
| 0 | 1 | 10 | 10 |
| 1 | 2 | 8 | 9 |
| 2 | 3 | 6 | 8 |
| 3 | 4 | 4 | 7 |
| 4 | 5 | 2 | 6 |
print('1 ---------')
print(df_query.query('A > B'))
print('\n2 ---------')
print(df_query.query('A < B and B < `C C`'))
print('\n3 ---------')
print(df_query.query('B == `C C`'))
print('\n4 ---------')
list_query = [2, 4, 8]
print(df_query.query('B in @list_query'))
print('\n5 ---------')
print(df_query.query('A > 3'))
1 --------- A B C C 4 5 2 6 2 --------- A B C C 1 2 8 9 2 3 6 8 3 --------- A B C C 0 1 10 10 4 --------- A B C C 1 2 8 9 3 4 4 7 4 5 2 6 5 --------- A B C C 3 4 4 7 4 5 2 6
df_query_2 = pd.DataFrame({'A': ["abc", "def", "ghi"], 'B': ["jkl", "mno", "pqr"], 'C C': ["stu", "vwl", "yz"]})
df_query_2.query("`C C`.str.startswith('st')")
| A | B | C C | |
|---|---|---|---|
| 0 | abc | jkl | stu |
ll = ["abc"]
df_query_2.query("A in @ll and `C C`.str.startswith('st')")
| A | B | C C | |
|---|---|---|---|
| 0 | abc | jkl | stu |
df_query_2.query("A.str.contains('d.f')")
| A | B | C C | |
|---|---|---|---|
| 1 | def | mno | vwl |