Two animations from Wikipedia of the Dijkstra algorithm¶
Finding shortest paths from initial node 1 to every other nodes
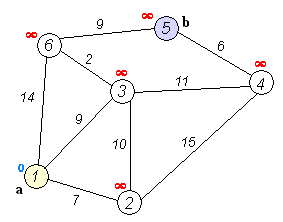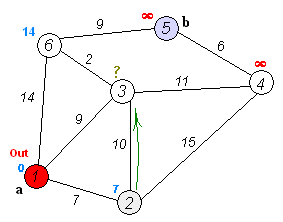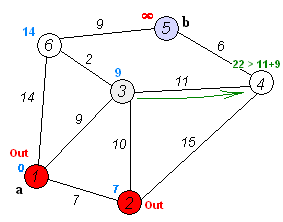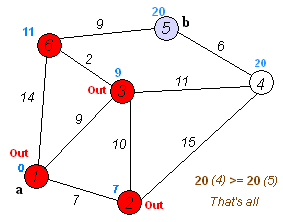
Animation that shows the propagation of the research of shortest paths

Finding shortest paths from initial node 1 to every other nodes
Animation that shows the propagation of the research of shortest paths
1 function Dijkstra(Graph, source):
2
3 for each vertex v in Graph.Vertices:
4 dist[v] ← INFINITY
5 prev[v] ← UNDEFINED
6 add v to Q
7 dist[source] ← 0
8
9 while Q is not empty:
10 u ← vertex in Q with min dist[u]
11 remove u from Q
12
13 for each neighbor v of u still in Q:
14 alt ← dist[u] + Graph.Edges(u, v)
15 if alt < dist[v] and dist[u] is not INFINITY:
16 dist[v] ← alt
17 prev[v] ← u
18
19 return dist[], prev[]Initialize (initialisation):
a. A list of distances to origin to inifinity for each node expect for origin where distance is 0
b. A list tracing the nodes that remain to be processed initialized with all nodes in the list
c. A empty dict that will save the predecessor of each node in the path from origin to this node.
While list tracing the nodes that remain to be processed is not empty (ie some nodes remains to be processed):
a. Take the nodes with shortest path from origin from the nodes that remain to be processed and remove it from this list (get_closest_node)
b. Process the node: for all of its neighbours update the distance from origin if the path passing by the current node is shorter than the previous path or if no path existed (update_distances); for the neighbours with path updated, so set the precedent node to the current one
Return the list of distances from origin and the list of precedent nodes
Once the algorithm has run, one can use the predecessor dict to backtrack from any final node to origin and return the path.
from collections import defaultdict
def dijkstra(edges, origin_node, nb_nodes):
# Create the graph as a dict with keys being the origin nodes and value being a list of its neighbours
graph = defaultdict(list)
for (node_from, node_to, edge_weight) in edges:
graph[node_from].append((node_to, edge_weight))
# Initialize variables
nodes_to_process = [i for i in range(nb_nodes)]
shortest_path = {i: float('inf') for i in range(nb_nodes)}
shortest_path[origin_node] = 0
predecessor = dict()
# While some nodes remain to be processed
while nodes_to_process:
# Get closest node among nodes to be processed and remove it from the list of nodes to process
dict_tmp = {x:y for x, y in shortest_path.items() if x in nodes_to_process}
node = sorted(dict_tmp, key=dict_tmp.get)[0]
nodes_to_process.remove(node)
# Process the node, ie update its neighbour distances if the distance passing by this node is shorter
for neighbour, neighbour_distance in graph[node]:
if shortest_path[neighbour] > shortest_path[node] + neighbour_distance:
shortest_path[neighbour] = shortest_path[node] + neighbour_distance
predecessor[neighbour] = node
# Once every node has been processed return the shortest paths and the predecessor to backtrack the path
return(shortest_path, predecessor)
def retrieve_path(predecessor, origin_node, final_node):
# if node is origin it has no predecessor (special case) and just return it
if final_node == origin_node:
return([origin_node])
# if node is not reachable return nothing
if final_node not in predecessor:
return(None)
node, path_from_origin = final_node, []
# while origin_node has not been reached add the node to the path and so to its predecessor
while node != origin_node:
path_from_origin = [node] + path_from_origin
node = predecessor[node]
return([origin_node] + path_from_origin)
edges = [(0, 1, 1), (1, 3, 2), (0, 3, 6), (1, 2, 1), (3, 1, 1)] # with edges values
distance, predecessor = dijkstra(edges, 0, 4)
retrieve_path(predecessor, 0, 3)
[0, 1, 3]
The algorithm can be improved by using a heap that will keep the distances of the nodes to origin. When processing a node and its neighbours, the new distances will be added to the heap even if they are not better than the precedent distances. The structure of the heap insures that the best path for any node will be pop first and hence we store the distance of this node only the first time we pop it. Also we process a node and its neighbours (ie add the neighbours new distances to the heap) only the first time the node has been pop. Otherwise if some loop exists in the graph the algorithm will never end. The advantage of using a heap is that it keeps sorted values in a O(log n) complexity.
import heapq
from collections import defaultdict
def dijkstra(edges, origin_node, nb_nodes):
# Create the graph as a dict with keys being the origin nodes and value being a list of its neighbours
graph = defaultdict(list)
for (node_from, node_to, edge_weight) in edges:
graph[node_from].append((node_to, edge_weight))
heap_distance = [(0, origin_node, None)]
shortest_path, predecessor = dict(), dict()
# while some nodes with given distance remain in the heap
while heap_distance:
node, node_distance, node_predecessor = heapq.heappop(heap_distance) # pop the closest node
# if this node has not been pop before (ie with a better path) store its current path and process it
if node not in shortest_path:
shortest_path[node] = node_distance
predecessor[node] = node_predecessor
for neighbour, neighbour_distance in graph[node]:
heapq.heappush(heap_distance, (shortest_path[node] + neighbour_distance, neighbour, node))
return(shortest_path, predecessor)
edges = [(0, 1, 1), (1, 3, 2), (0, 3, 6), (1, 2, 1), (3, 1, 1)] # with edges values
distance, predecessor = dijkstra(edges, 0, 4)
retrieve_path(predecessor, 0, 3)
[0, 1, 3]
from collections import defaultdict
def dijkstra(edges, origin_node, nb_nodes):
# initialisation
def initialisation(origin_node, nb_nodes):
nodes_to_process = [i for i in range(nb_nodes)]
shortest_path = {i: float('inf') for i in range(nb_nodes)}
shortest_path[origin_node] = 0
predecessor = dict()
return(nodes_to_process, shortest_path, predecessor)
# get_closest_node returns node in not_visited with minimum path and remove it from not_visited
def get_closest_node():
dict_tmp = {x:y for x, y in shortest_path.items() if x in nodes_to_process}
closest_node = sorted(dict_tmp, key=dict_tmp.get)[0]
nodes_to_process.remove(closest_node)
return(closest_node)
# update_distances updates the path of the neighbours of node
def update_distances(node):
for neighbour, neighbour_distance in graph[node]:
if shortest_path[neighbour] > shortest_path[node] + neighbour_distance:
shortest_path[neighbour] = shortest_path[node] + neighbour_distance
predecessor[neighbour] = node
# Create the graph as a dict with keys being the origin nodes and value being a list of its neighbours
graph = defaultdict(list)
for (node_from, node_to, edge_weight) in edges:
graph[node_from].append((node_to, edge_weight))
nodes_to_process, shortest_path, predecessor = initialisation(origin_node, nb_nodes)
while nodes_to_process:
closest_node = get_closest_node() # get the closest node
update_distances(closest_node) # update shortest path of its neighbours
return(shortest_path, predecessor)
import heapq
from collections import defaultdict
def dijkstra(edges, origin_node, nb_nodes):
# initialisation
def initialisation(origin_node, nb_nodes):
nodes_to_process = [i for i in range(nb_nodes)]
heap_distance = [(0, origin_node, None)]
heapq.heapify(heap_distance)
shortest_path, predecessor = dict(), dict()
return(heap_distance, shortest_path, predecessor)
# get_min returns node with minimum no worry if this node has already been visited as it will be updated only
# the first time we pop it (and by construction of heap it insures that first time is the shortest path)
def get_closest_node():
closest_node_distance, closest_node, closest_node_predecessor = heapq.heappop(heap_distance)
if closest_node not in shortest_path:
shortest_path[closest_node] = closest_node_distance
predecessor[closest_node] = closest_node_predecessor
return(closest_node, True) # we will only process the node if it's the first time we see it
return(closest_node, False) # otherwise we won't process it (risk of inifite loop)
# update_distances for every neighbours of the node add the distances passing by this node even if the node is
# already in the heap. By construction of the heap, the first time we will pop wille have its shortest path
def update_distances(node, to_process):
# only process the node if it is the first time we see it
if to_process:
for neighbour, neighbour_distance in graph[node]:
heapq.heappush(heap_distance, (shortest_path[node] + neighbour_distance, neighbour, node))
# Create the graph as a dict with keys being the origin nodes and value being a list of its neighbours
graph = defaultdict(list)
for (node_from, node_to, edge_weight) in edges:
graph[node_from].append((node_to, edge_weight))
heap_distance, shortest_path, predecessor = initialisation(origin_node, nb_nodes)
while heap_distance:
closest_node, to_process = get_closest_node()
update_distances(closest_node, to_process)
return(shortest_path, predecessor)